
SageMaker Model Monitoring Best Practices
Introduction to SageMaker Model Monitoring Best Practices Best practices for model monitoring in SageMaker are essential for any ML deployed […]
Introduction to SageMaker Model Monitoring Best Practices Best practices for model monitoring in SageMaker are essential for any ML deployed […]
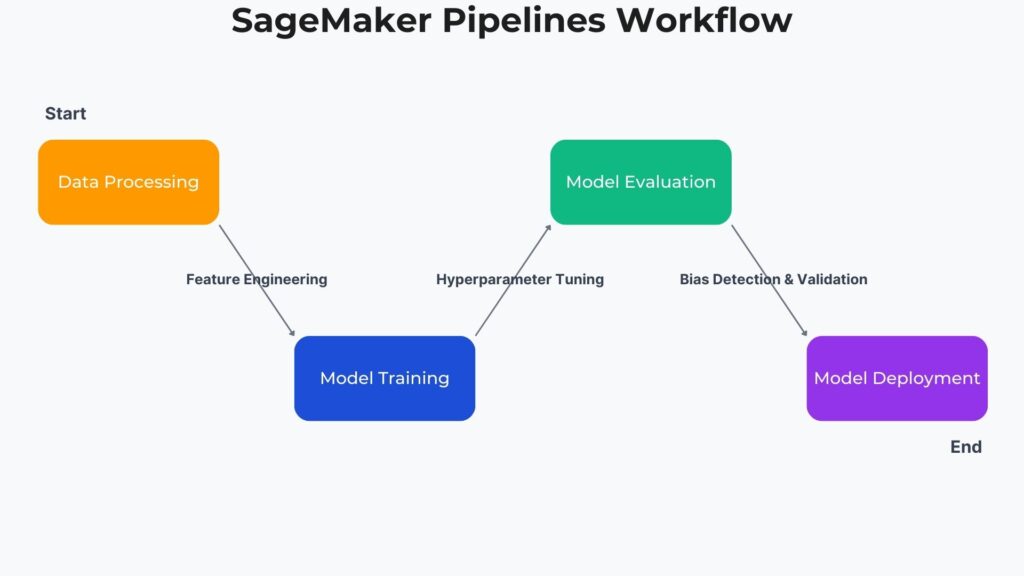
1. SageMaker Pipeline Workshop: An Introduction to ML Automation If you find building and deploying learning models overwhelming, then you
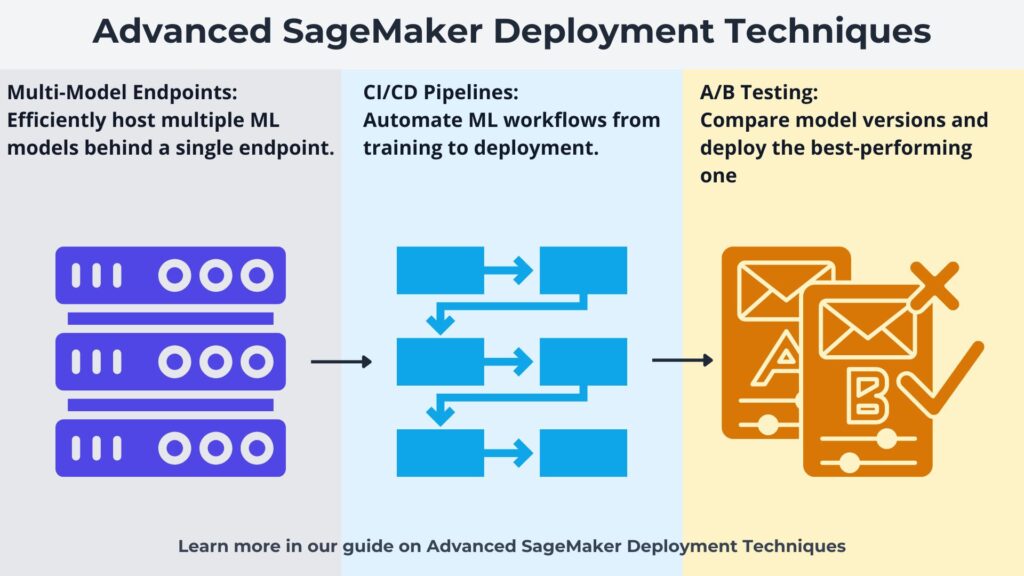
1. Introduction Advanced SageMaker Deployment Techniques enable AWS SageMaker to host ML models for efficient prediction and pattern recognition. Machine
Introduction This SageMaker overview for ML engineers explores AWS SageMaker, a service that supports commonly available ML frameworks and allows

Introduction Google originally designed the Apache Spark architecture for distributed and scalable big data processing, utilizing parallel processing architectures. It

Introduction: AWS MSK vs Confluent – Understanding the Right Choice for Kafka Kafka is a powerful service for streaming real-time

Introduction We explored that Apache Spark has become the go-to solution for large-scale data processing. However, we must focus on

1. Introduction: How Apache Spark for Big Data Analytics is Driving Innovation Apache Spark for big data analytics has solidified

Introduction: Unlocking TensorFlow’s Full Potential for Big Data Projects Information technology’s rapid advance causes data generation to grow continually. Subsequently,

Introduction: Unlocking TensorFlow’s Potential for Big Data TensorFlow is an important tool for analyzing and processing big data, and its