
Introduction
Therefore, efficient TensorFlow data pipelines facilitate seamless data loading, data cleaning in TensorFlow, and pipeline creation. Also, building efficient data pipelines using TensorFlow’s tools optimizes large-scale data processing. Additional TensorFlow tools include TensorFlow data visualization and TensorFlow data augmentation techniques, which improve model insights.
Importance of Efficient TensorFlow Data Pipelines
Efficient data pipelines are the foundation for effective data handling in several ways, including
enhanced processing speed and model performance. They also enable scalable and reusable workflows for big data applications and allow streamlined and optimized pipelines.
Streamlined pipelines automate data processing steps for faster workflows. This reduces manual intervention, making data handling more efficient. Automation also minimizes data flow errors and inconsistencies. Streamline pipelines also boost productivity by simplifying complex tasks.
On the other hand, optimized pipelines improve resource management and computational efficiency. They can handle large datasets smoothly by using batching and parallel processing. Another benefit is enhanced model training performance through minimizing memory usage. These benefits cable scalable solutions for big data applications.
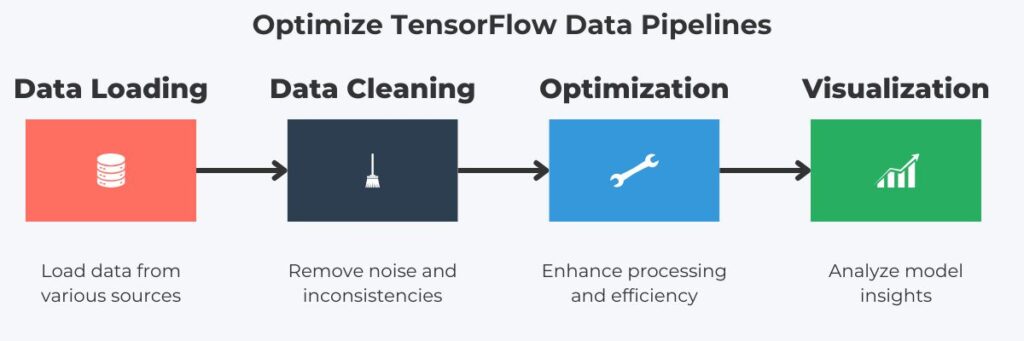
Loading and Preparing Data in TensorFlow
Effective data loading is the primary component of efficient TensorFlow data pipelines. Subsequently, TensorFlow provides tools for data loading, allowing developers to build these. First, TensorFlow supports various data file formats, including CSV, JSON, and streaming data. Also, TensorFlow provides batch processing that makes loading large datasets memory-efficient.
Preparation is the next logical step once data is loaded into the pipeline, making it essential for high-performance data pipelines. Therefore, TensorFlow provides the tf.data API that enhances data preparation speed.
Key Benefits of Using Efficient TensorFlow Data Pipelines
The tf.data API allows developers to set up automated data loading, transformation, and batching, improving data preparation speed. It also supports parallel data load that increases processing speed. Another key benefit is that developers can establish compatibility across local and cloud environments. Finally, it is modular and reusable, making it ideal for complex workflows.
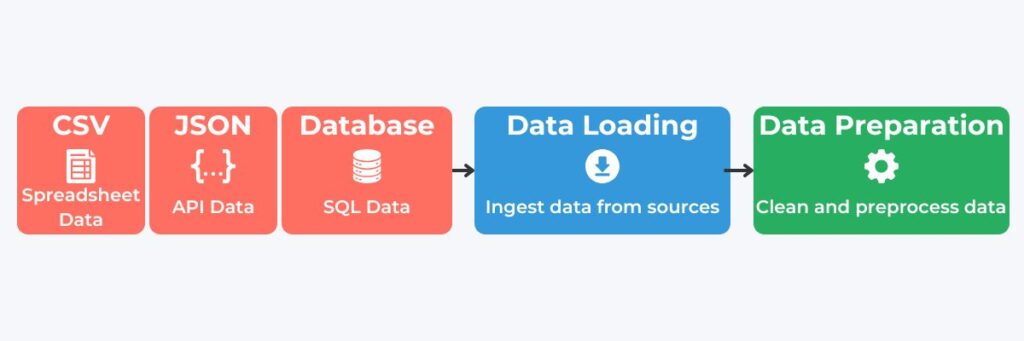
Cleaning and Transforming Data for TensorFlow Pipelines
Data cleaning in TensorFlow begins by removing noise and inconsistencies, crucial for accurate and reliable model outcomes. Data cleaning consists of several steps, including managing missing values using imputation or deleting techniques. This improves model training accuracy. Another step is standardization and scaling, which ensures data consistency. Data consistency is essential for scalable models and reduces the risk of overfitting with clean, standardized inputs. Machine learning performs better when categorical data is encoded, an important data-cleaning step. TensorFlow supports these steps through preprocessing layers to aid streamlining. By managing missing values, standardizing, and encoding data, data cleaning in TensorFlow enables consistent, high-quality inputs that reduce overfitting and improve model stability.
Additional data cleaning tools include outlier detection and data normalization. Outlier detection and removal further enhances data quality and model reliability by removing data that skews data distribution. Data normalization scales features to a similar range, which helps models learn patterns more effectively and improve training stability.
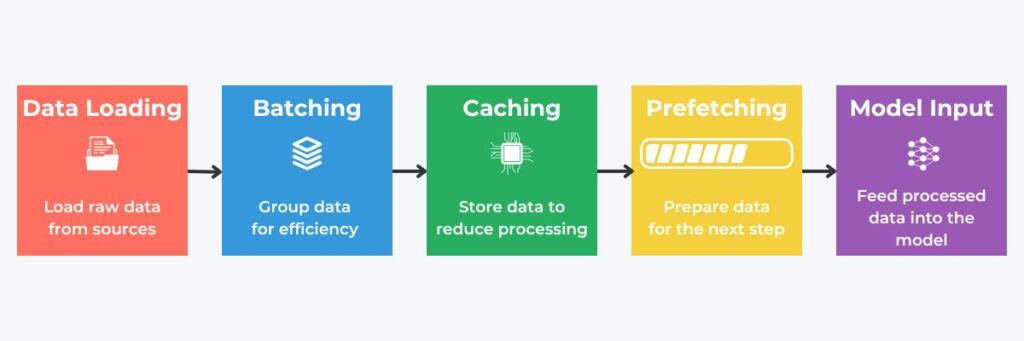
Building and Managing Data Pipelines with tf.data API
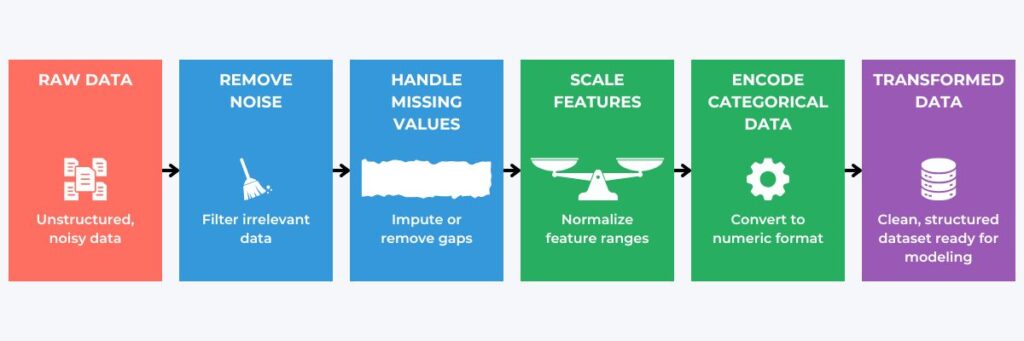
We have established what is needed for effective pipelines consumed by machine learning models. We now consider using the tf.data API, which is essential for creating efficient TensorFlow data pipelines. It automates the critical processes, including loading, batching, and transformation. It also allows pipelines to manage memory efficiently, which is crucial for large datasets. Additionally, the tf.data API enables the construction of reusable pipeline structures that simplify iterative model development.
Several techniques are available for pipelines to manage memory efficiently; two examples include prefetching and caching. Prefetching allows data to be loaded in advance, ensuring a continuous data supply while minimizing idle time during model training. Meanwhile, caching stores processed data in memory or disks to reduce the need to reload or reprocess data. Therefore, it accelerates subsequent pipeline runs.
Several other techniques include parallel data loading, batching and shuffling, pipeline reusability, and map and filter operations. Parallel data loading allows processes to load multiple data files simultaneously. This helps to improve data ingestion speed and reduce wait times for large datasets. Batching and shuffling involve processes grouping data into batches and shuffling it for each epoch. Subsequently, this improves memory efficiency and enhances model generalization.
Pipeline reusability enables processes to create modular, repeatable structures. These structures simplify adjustments and reuse across different training sessions or model iterations. Map and filter operations allow processes to apply transformations and filters directly within the pipeline. Processes can perform efficient data preprocessing without separate scripts.
The tf.data API also provides several techniques to improve pipeline execution. Batch processing optimizes training performance. Another technique is shuffling and repeat operations, which enhance model generation. These are complemented by real-time pipeline adjustments that support dynamic training needs.
Data Visualization with TensorBoard
This section describes TensorFlow data visualization to help operators gain insights into pipeline and model metrics. While automating data pipelines has many advantages, operator involvement is essential, especially to correct any inherent errors or problems that may arise. Therefore, TensorFlow includes the TensorBoard tool, which facilitates participation by operators and developers. It assists people by offering insights into pipeline and model metrics. TensorBoard also helps with debugging by providing visualizations for loss, accuracy, and layer structures. Additionally, custom visualizations enable tailored insights into data flow. Another tool is real-time graphs that allow for timely adjustments and fine-tuning.
Utilizing TensorFlow data visualizations, such as histogram tracking and comparative visualizations, can improve model analysis and debugging. TensorFlow’s histogram visualizations help track weight distribution changes over time. Meanwhile, TensorBoard’s comparative visualizations allow users to evaluate multiple model runs side by side.
Data Augmentation Techniques in TensorFlow
Another essential technique that TensorFlow provides is data augmentation techniques. Therefore, this section explores TensorFlow data augmentation techniques that increase data variety and help prevent overfitting. These diversify training data and reduce overfitting. Also, TensorFlow data augmentation techniques like rotation, scaling, and cropping can create robust models that generalize well. Another set of techniques is sampling techniques that manage dataset imbalances for training. TensorFlow allows developers to implement real-time data augmentation within data pipelines.
Data augmentation also improves model performance in several ways. Increased dataset variety enhances model robustness. Data augmentation also helps make models more generalized, performing better on unseen data. As mentioned earlier, synthetic variations help prevent overfitting.
Conclusion
Developers who build efficient TensorFlow data pipelines are better able to enhance model performance. Structured data cleaning in TensorFlow is essential to optimizing data pipelines, enhancing model performance, and ensuring effective big data handling. TensorFlow’s tf.data API provides robust tools for creating scalable pipelines. Developers can derive insights into model training through TensorFlow’s visualization and augmentation tools. Building reliable data pipelines is critical to efficient big data handling.
For those considering managed ML platforms, Amazon SageMaker provides an efficient way to handle TensorFlow pipelines without manual infrastructure management.