
Introduction to AWS ML Data Preprocessing
In this article, we explore how AWS ML data preprocessing can streamline your machine learning workflows. Real-world data is messy because it has been out in the wild and is unmaintained. It is often erroneous, inconsistent, and incomplete, resulting in both machine learning and inference processes yielding erroneous results. Additionally, statistics from different categories have different scales, with one category having undue influence over any results.
Hence, AWS preprocessing is essential to any ML activity to ensure clean data that will lead to more accurate results. Errors introduce noise, and preprocessing removes this noise and data inconsistencies. Another issue with real-world data is that, in many cases, it is not the format for machine learning algorithms to handle without difficulties. Preprocessing also ensures data is in the correct format for machine learning and inference engines. Good data saves time during training and debugging since there is less training to accommodate poor data.
It is also important to automate data preprocessing in AWS since it is often voluminous and comes in at a high rate. Manual processes can often introduce new errors into data. AWS tools can easily automate preprocessing because they are highly scalable and seamlessly integrate with AWS ML tools.
1. Why Preprocessing Matters
ML models are still data processing engines. Therefore, the term “garbage in, garbage out” applies equally to them as to all other computational engines. Subsequently, this fact makes AWS ML data preprocessing necessary. ML models are unable to discern the quality of input data. Therefore, they base their response on the quality of the presented data. Consequently, it is essential to ensure that clean and structured data is fed to the ML. This is during both training and inference.
AWS ML data preprocessing performs many tasks, some more common than others. Missing values are often the common issue due to unreliable sources, and preprocessing techniques infer these values. Also, preprocessing needs to convert data formats to those that match the input requirements of machine learning algorithms. Another issue is when outliers have undue influence over the population, e.g., incomes with a small minority of excessive incomes.
There are also problems when one dimension has a scale of a far greater magnitude than another dimension, distorting the model’s representation. Data needs encoding when certain aspects are qualitative, but ML algorithms can only accept quantitative values.
AWS ML data preprocessing automates these preprocessing activities. One will easily conclude that performing these tasks manually is extremely time-consuming and error-prone. It is evident that error-prone manual preprocessing defeats its very purpose.
2. Overview of AWS Tools for Data Preprocessing
Here’s a visual overview of how AWS services integrate in a typical ML data preprocessing workflow:
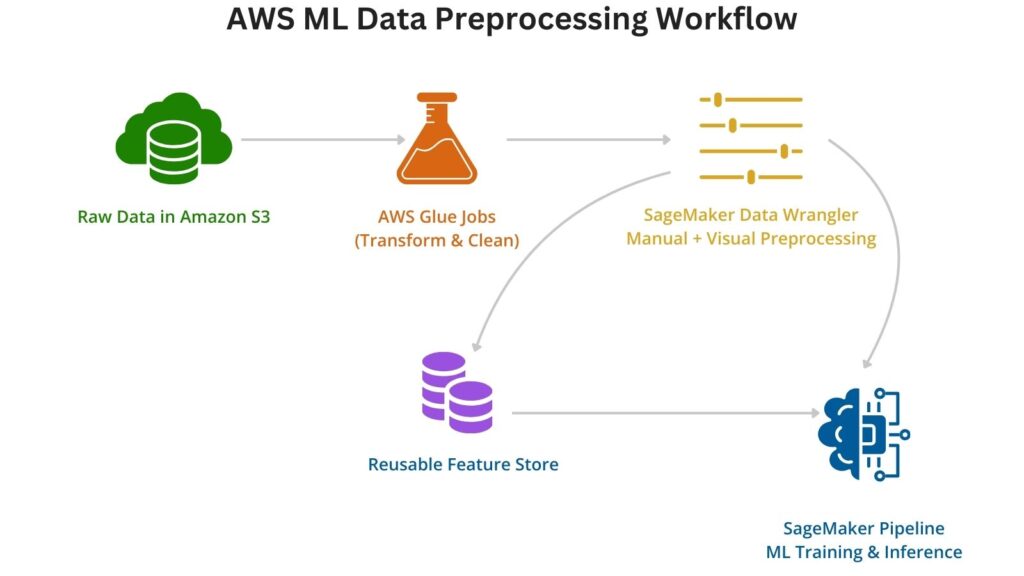
AWS ML data preprocessing integrates several AWS services that clean and structure data for training and deployed inference. The core service that performs data preprocessing heavy lifting is AWS Glue, which can run Apache Spark jobs. AWS Glue has the built-in ability to perform extract, transform, and load (ETL) for several reasons. It seamlessly integrates with a wide range of AWS data storage services, allowing efficient and scalable data transfer. Also, AWS Glue supports built-in transformations, including mapping, filtering, joining, and cleaning. It can also automatically generate PySpark-based scripts and support custom transformations written in either Python or Scala.
When extracting data, AWS Glue can apply crawlers to various data sources to discover schemas and build a Data Catalog. On the output side, it supports partitioning and data format conversion; a good example is CSV to Parquet. This is a particularly important consideration since a significant data source is spreadsheets that output data as CSV.
AWS Glue also orchestrates with AWS Workflows and integrates with AWS Step Functions. This makes it indispensable for AWS ML data processing.
While it is vital to minimize manual involvement with preprocessing, some human guidance is always needed. Amazon SageMaker Data Wrangler provides visual preprocessing and is integrated with notebooks, allowing manual intervention when needed.
Workflow orchestration is essential for any AWS ML data preprocessing, and AWS Lambda, coupled with AWS Step Functions, supports this.
The other core AWS service supporting data preprocessing is Amazon S3, through its general purpose object storage. It seamlessly integrates with AWS Services, including Glue and SageMaker, allowing for staging and storing of both raw and clean data.
3. Automating the Data Cleaning Process
As mentioned, AWS Glue does the heavy lifting for AWS ML data processing through automated AWS Glue Jobs. There are two parts to utilizing AWS Glue Jobs in data preprocessing. One is the actual data transformation or transformations, and the other is scheduling or triggering these transformations.
The transformations that AWS Glue Jobs perform use scripts written in scripting languages, including Python and Scala. These scripts run on the Spark framework, which performs processing at scale, partitioning the work across multiple processing nodes. Thereby leveraging the parallel nature of these tasks, especially when large datasets are involved.
Another advantage of AWS Glue is that it automatically generates PySpark or Scala scripts for specified data transformations. Engineers can design these transformations visually using the Glue Studio visual editor, where they can drag and drop the following transformations:
- ApplyMapping
- Filter
- Join
- DropFields
- RenameField
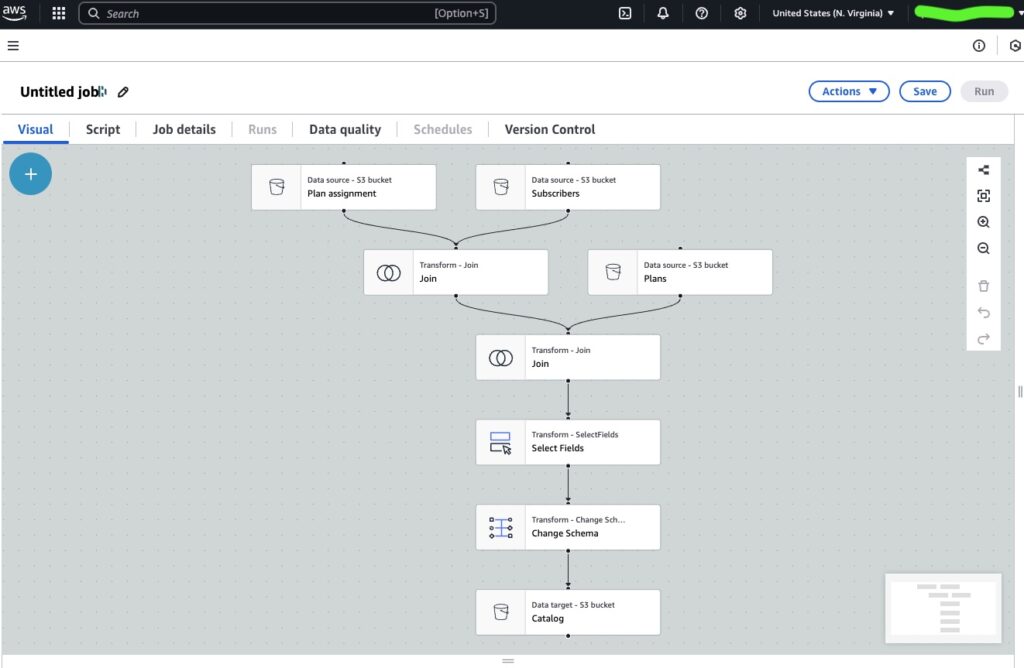
Engineers also have the option to write or edit the script manually in either Python, using the PySpark framework, or Scala. They can also switch easily between script mode and visual mode.
The other aspect of AWS ML data preprocessing is setting up when these data transformation jobs run. They can run on a predetermined schedule that is set up using cron expressions that trigger the AWS Glue jobs. Otherwise, engineers can set up event triggering for these transformations, like new data stored in AWS S3 buckets.
A simple example is with two S3 buckets and an AWS Glue job that cleans raw data. One bucket has raw data written into it from an external data source. The other bucket has clean data written into it from the AWS Glue Job that performs the transformations. Triggering for the Glue Job is either on a schedule or when raw data is written into the bucket.
4. Preprocessing with SageMaker Pipelines
AWS ML data preprocessing does not operate in a vacuum but must be part of the continuous delivery pipeline. Engineers use SageMaker pipelines to integrate data preprocessing with other stages of ML training, deployment, and monitoring. These subsequent stages are predominately SageMaker services that are responsible for training, managing, deploying, and monitoring these models. More sophisticated pipelines also have model retraining as part of their workflow.
An essential SageMaker stage in this workflow is the SageMaker Data Wrangler. While automation is key to AWS ML data preprocessing, unsupervised automation can cause more problems than it solves. It is not a panacea since preprocessing often requires value judgment and human oversight. When this human oversight is enhanced by AI tools, the data preprocessing workflow becomes extremely powerful.
Data Wrangler’s design intention is to integrate human oversight and judgment with automated transformation seamlessly. It provides a visual interface for engineers to intervene in data preprocessing with notebook integration, giving engineers a wide range of tools. Engineers can enhance their oversight over automated processes with powerful AI tools.
Automated processes form part of the SageMaker pipeline that transforms, normalizes, and encodes the raw data. With oversight provided by Data Wrangler, the data is exported to training-ready format.
Another important piece for preprocessing is the Feature Store that introduces reusability into ML workflows. Features are the input variables in ML models and support both training and inference use cases. These ensure consistency within ML models and between ML models.
5. Best Practices for AWS ML Data Preprocessing
Building data preprocessing workflows integrated with SageMaker still requires established best practices for maximum benefit. Similar to software engineering processes and workflows, it is essential to validate each stage and transformation. Validating the transformation stages within AWS Glue involves checking job logs and reviewing the transformed data in the target location. S3 storage also requires validation by inspecting file format, size, and schema consistency following each stage. Engineers should also check the built-in data preview and summary statistics to validate SageMaker Data Wrangler prior to exporting.
This article advocated automation over manual processes, which is in itself a best practice for data preprocessing. Engineers should always identify repeatable processes which are always an opportunity for automation. However, engineers must always balance this with the ability to review these processes and manual oversight.
An important part of validating AWS ML data processing are logs, and all these stages effortlessly integrate with AWS CloudWatch. It is essential to log transformations to CloudWatch for monitoring their efficacy and checking their correctness. Another consideration is that some of these transformations have built-in logging tools that engineers should make use of.
Also, engineers should version datasets and transformation logic for the same reasons that they version code and ML models. This makes these processes repeatable for analysis, debugging, and troubleshooting. Additionally, engineers can revert to prior versions whenever upgrades introduce any issues.

6. AWS ML Data Preprocessing Challenges and Limitations
AWS ML data preprocessing addresses many input data issues for training and applying inferences to models. However, there are several issues around automated preprocessing that engineers need to consider when building these workflows. AWS Glue has a library of transformations that engineers can configure using its visual interface. However, there are many issues with data from sources that require a more complex solution. Therefore, engineers must write custom scripts to handle these more complicated cases.
In SageMaker model monitoring best practices, we discussed model drift, and this is also applicable to the input data. Therefore, engineers must also monitor input data and update processing rules when needed. Additionally, they should look for opportunities to enhance the pipeline to automate updating processing rules.
AWS charges for all its services, including Glue jobs, S3 usage, and SageMaker and engineers should always look to minimize costs. Several low-hanging fruit do exist where one is using spot instances for Glue and SageMaker. Another is using Glacier for long-term storage of models and logs that are over six months old.
Organizations also need to factor in learning curves for their engineers. These include understanding Glue scripting and building SageMaker pipelines.
7. Final Thoughts and Next Steps
AWS ML data preprocessing automation leverages the AWS ecosystem to, at a minimum, ensure data correctness, balance, completeness, and structure. Other important aspects include consistency, validity, timeliness, outliers, and noise. It automates all repeatable steps for efficiency and error minimization while providing for human oversight when needed.
We have briefly mentioned that some activities do involve a steep learning curve. Therefore, it is highly useful to try out Glue and SageMaker Pipelines in a sandbox project. Acquiring hands-on learning of these services will help you in building out these workflows for real-world applications.
Existing ML workflows can also benefit from integrating preprocessing into their pipelines. We encourage readers to start investigating this with the ML workflow they are involved with. For those working with TensorFlow, you can extend your learning by exploring how to build efficient data pipelines within the framework itself in this article.
Data will continue to scale in size and complexity, making it imperative to master preprocessing workflows for machine learning platforms.
Further Reading
If you’re looking to deepen your understanding of AWS data pipelines and machine learning workflows, these resources are highly recommended:
- Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines
- Machine Learning Engineering with Python: Manage the production life cycle of machine learning models using MLOps with practical examples
- Scalable Data Streaming with Amazon Kinesis: Design and secure highly available, cost-effective data streaming applications with Amazon Kinesis
Affiliate Disclaimer
As an Amazon Associate, AI Cloud Data Pulse earns from qualifying purchases. This comes at no extra cost to you and helps support the site’s content and maintenance.
References
- AWS Glue Documentation
https://docs.aws.amazon.com/glue/ - Amazon SageMaker Developer Guide
https://docs.aws.amazon.com/sagemaker/ - Amazon SageMaker Data Wrangler
https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler.html - AWS Step Functions
https://docs.aws.amazon.com/step-functions/ - Efficient TensorFlow Data Pipelines
https://www.aiclouddatapulse.com/efficient-tensorflow-data-pipelines/