Introduction
Automated data ingestion in AWS prepares data generated by many external sources for analysis, insights, and understanding. In addition to collecting data from these sources, we need to process this data and store it in appropriate storage systems. This allows data analysis systems to access this data efficiently and cost-effectively. These data analysis systems provide the necessary insight and understanding for users to make informed decisions. Automating these steps makes the process highly efficient and far less prone to error.
We refer to data from external sources as raw data since it is in a form that many analysis systems cannot effectively handle. The most common examples are unstructured data, data containing inconsistencies and errors, and data volumes too large for storage. Unprocessed raw data is messy, and when it has no structure, then it is difficult to analyze. When there is no optimization, then it is costly and inefficient.
Automated data collection and ingestion in AWS go hand in hand. Data collection gathers information from external sources, processes it, and transfers it to suitable storage devices. Combined, they enable a streamlined and automated data pipeline.
1. Understanding Automated Data Ingestion in AWS
Data ingestion processes data gathered from diverse sources that data analytic tools and systems can adequately analyze. These include removing errors and inconsistencies, deleting irrelevant data, and properly structuring it. These systems often analyze large data volumes generated at high speed, making manual ingesting processes ineffective.
Automated data ingestion is where all the steps are automated, and there is no manual intervention. This makes the ingestion process efficient and removes many errors. Therefore, it is a crucial component of any data analysis.
Data collection in AWS is gathering data from various sources and loading it into the AWS cloud. These sources include applications, devices, or services external to the AWS Cloud. There are several AWS services that perform data collection in AWS, including Amazon Kinesis Data Streams. Many sources mentioned above can publish real-time data to this service.
On the other hand, AWS data ingestion processes and transfers data into AWS storage systems for analysis and insights. An AWS service that performs ingestion is AWS Glue, which transforms data from multiple sources and loads it into data lakes or warehouses.
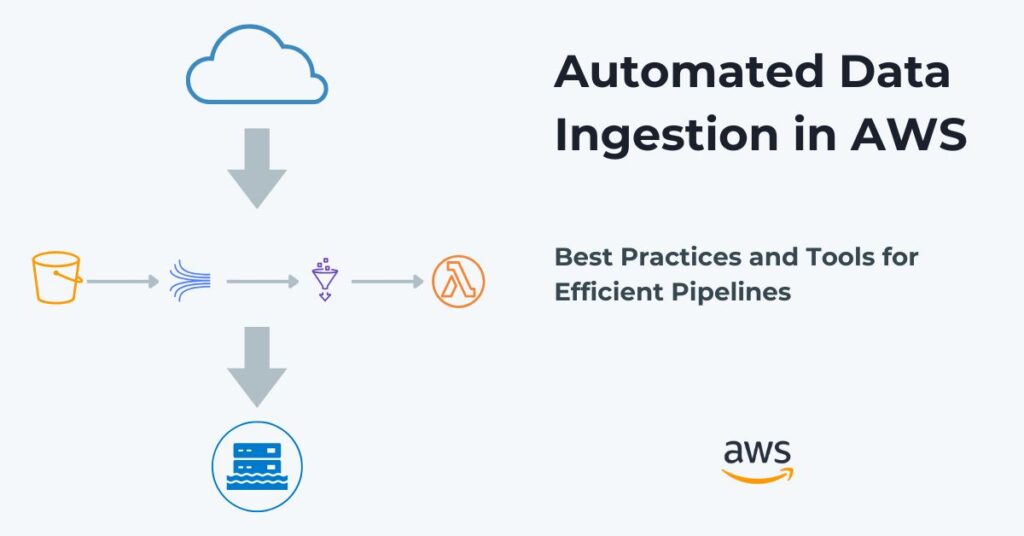
There are other AWS services that support ingestion besides AWS Glue. S3 serves as a landing zone for both raw (collected) data and processed (ingested) data. It is a versatile tool for both automated data collection and ingestion in AWS.
AWS Lambda functions often perform data ingestion and provide fine-grain scalability. They can work in conjunction with Kinesis Data Firehose to perform automated data collection and ingestion in AWS.
2. Key Technologies for Data Ingestion in AWS
2.1 AWS Services for Data Ingestion
2.1.1 AWS S3
S3 is the dominant entry point for general-purpose data collection and data ingestion jobs at scale. It serves as a scalable landing zone for both raw and processed data from multiple ingestion sources. However, it also tightly integrates with AWS services that perform data ingestion and provides event triggering to these ingestion services. It also supports direct uploads from external sources using pre-signed URLs, SDKs, or the S3 API. S3 provides lifecycle policies for stored data for secure and cost-efficient long-term data storage.
2.1.2 Amazon Kinesis
Amazon Kinesis is a versatile streaming engine that can ingest real-time data from external sources for immediate processing. It supports high-throughput, low-latency streaming ingestions that can support millions of records per second. Like S3, it integrates with other AWS ingestion services to trigger downstream processing automatically. It also enables parallel data ingestion and scalability by supporting data partitioning through shards. Kinesis has built-in retention that allows reprocessing of ingested data within a configurable time window.
2.1.3 AWS Glue
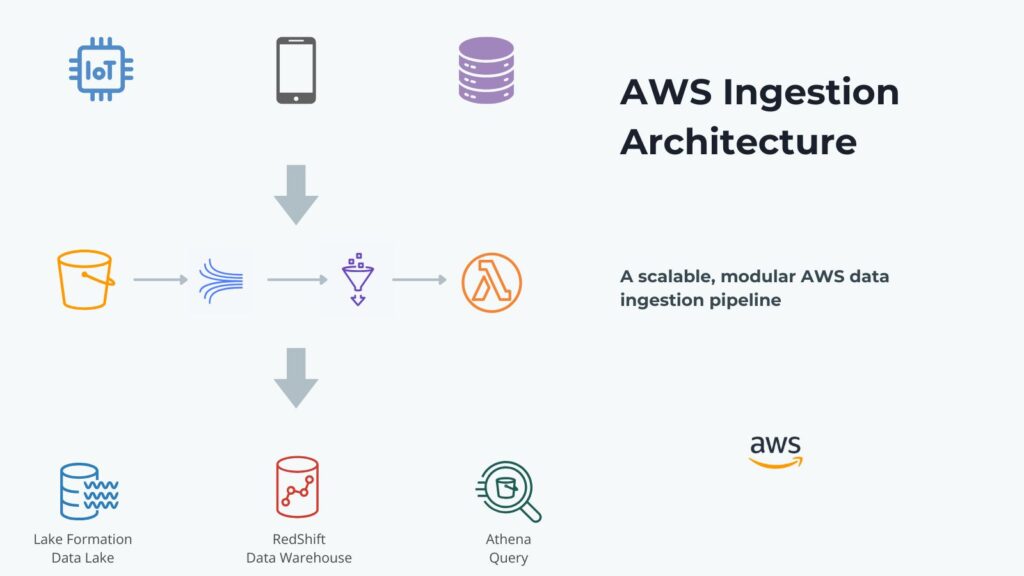
AWS Glue performs automated ingestion through ETL on data from multiple sources into data lakes or warehouses. It can either support schedule or event-driven jobs, allowing it to continuously ingest and process new data. AWS Glue includes Glue crawlers that scan and catalog ingested data, making it queryable through AWS services like Athena. It can unify ingestion pipelines by integrating with S3, RDS, Redshift, and other data stores.
2.1.4 AWS Lambda
AWS Lambda provides serverless processing of incoming data, eliminating the need to manage infrastructure. Each lambda function can either transform, filter, or route ingested data to other AWS services. In addition, it provides scalability for each of these functions and supports real-time ingestion by processing data immediately upon arrival. Besides processing data, it can automatically trigger other data ingestion workflows in response to events.
To see how ingested data is used in model training workflows, explore our Beginner’s Guide on TensorFlow Models.
2.2 How Data Collection Fits In
These primary AWS ingestion services seamlessly integrate with both external and internal data sources. These include AWS IoT Core, DynamoDB, and EventBridge, among others. Amazon service’s seamless integration makes automated data collection and ingestion in AWS part of an integrated data pipeline.
2.2 How Data Collection Fits In
These primary AWS ingestion services seamlessly integrate with both external and internal data sources. These include AWS IoT Core, DynamoDB, and EventBridge, among others. Amazon service’s seamless integration makes automated data collection and ingestion in AWS part of an integrated data pipeline.
3. Best Practices for Automated Data Ingestion
To effectively coordinate automated data collection and ingestion in AWS, it is necessary to follow established best practices.
3.1 Scalability and Performance Optimization
Collecting and ingesting data over set periods must be done efficiently, and the amount of data may fluctuate at different times. In some cases, we can predict data volume, and in others, we cannot predict. Therefore, the capacity of our collection and ingestion systems must scale according to the data currently present for ingestion.
S3 can partition data by organizing it with logical keys (e.g., data or region), similar to relation database indexes. This allows ingestion jobs to select only the relevant subsets and reduce read times. It also provides data compression that enables faster transfer and less I/O during ingestion, reducing the time needed.
Kinesis provides stream sharding, leveraging parallel processing to improve throughput where multiple producers and consumers can read and write simultaneously. Shards can scale in response to changing data loads and reduce bottlenecks during peak data flows. Dynamically distributing the workflow is crucial for real-time analytic pipelines.
AWS Glue provides Glue jobs and triggers that enable scalable, serverless ETL pipelines for structures or semi-structured ingestion. Glue triggers support timely and consistent ingestion workflows by automating job execution based on schedules or events. AWS Glue jobs perform ETLs efficiently by running in parallel and having tight integration with S3 partitioned and compressed data sources.
For deeper insight into processing large datasets efficiently, check out our Ultimate Guide on Apache Spark for Big Data Analytics.
3.2 Security and Compliance
Often, collected and ingested data is sensitive. It either contains private personal data or data that is commercially confidential, financially sensitive, or government-classified. Also, data handling is subject to regulatory controls imposed by authorities.
Controlling data access is critical to comply with security requirements and the AWS IAM service enables this through its roles and policies. Policies specify both access and denial to AWS resources to provide fine-grain access control to these resources. A role is a set of permissions that define actions allowed or denied for an AWS entity or user. These permissions are specified by the policy attached to it. Therefore, access to AWS resources by entities is controlled through roles assigned to these entities with policies attached to the roles.
Encryption is a fundamental principle in data security and unencrypted data is never tolerated in modern data processing systems. The first encryption principle, encryption at rest, stipulates that systems must encrypt stored data, and AWS provides KMS for this. The other is encryption in transit, which stipulates encrypting transmitted data, and SSL/TLS is the primary mechanism to achieve this.
Companies must have and enforce data governance policies, and AWS Lake Formation enables this within AWS. It enables fine-grain access control at different storage levels, including database, table, column, and row. Organizations can employ centralized policy management over data handling services, including Athena, Redshift, and Glue. It also integrates with AWS Cloud Trail for logging and auditing to provide visibility into data access and policy changes.
3.3 Monitoring and Cost Optimization
Companies should monitor their data ingestion for data degradation and latency issues. Data collection and ingestion in AWS seamlessly integrates with AWS CloudWatch for monitoring data degradation and latency.
Organizations should also focus on cost and continually seek opportunities to optimize cost. AWS provides Spot instances and Auto Scaling that enable cost optimization. They should design data ingestion for resilience whenever spot instances are terminated. This is because spot instances provide up to 90% savings. Auto-scaling helps manage costs by ensuring companies are not paying for unused resources.

4. Challenges in Automated Data Ingestion
Automated data collection and ingestion in AWS come with several challenges that engineers must adequately plan for.
4.1 Data Structure
Real-world data is messy and seldom clean, and its structure is often incomplete or non-existent. Even structured data has the issue of structure changing over time.
Engineers can apply AWS Glue Crawlers to raw data that automatically detect and catalog structures from unstructured or semi-structured data. These include JSON documents, logs, and XML data. Lambda functions and Glue jobs can perform preprocessing and normalization of raw data. They can clean, flatten, and convert raw formats into structured tabular forms. When Glue Data Catalog catalogs metadata, it can store this in S3 using partitioning. This enables downstream querying with Athena or Redshift Spectrum.
Engineers can accommodate schema evolution through schema versioning using the Glue Schema Registry, which is applied to ingestion workflows. Athena provides column projection that can query data with evolving schemas without reprocessing the dataset. Engineers should also build Glue jobs that handle partition evolution and contain schema compatibility settings. Whereby then can gracefully handle new columns, missing fields, or data type changes.
4.2 Latency
Latency is an issue for real-time data streaming, and good pipeline design can mitigate these issues. Transformation overheads can introduce latency and preprocessing at the edge with AWS IoT, or lightweight Lambda functions can minimize these. Kinesis provides sharding that enables a horizontally scalable solution for streaming, preventing throttling and reducing ingestion lag. While these address latency, it is never guaranteed, and we need to monitor for latency and respond appropriately actively. Here, we use AWS CloudWatch and Alarms to take a proactive approach to any latency issues in the pipeline.
4.3 Cost
A core attraction of cloud computing is cost management, and data ingestion pipelines are no exception. As mentioned earlier, use spot instances at every opportunity to reduce cost significantly. Also apply auto-scaling to minimize idle capacity and their associated costs.
5. Future Trends in AWS Data Ingestion
Data ingestion is an evolving field, and new technologies are on the horizon, further transforming data collection and ingestion in AWS.
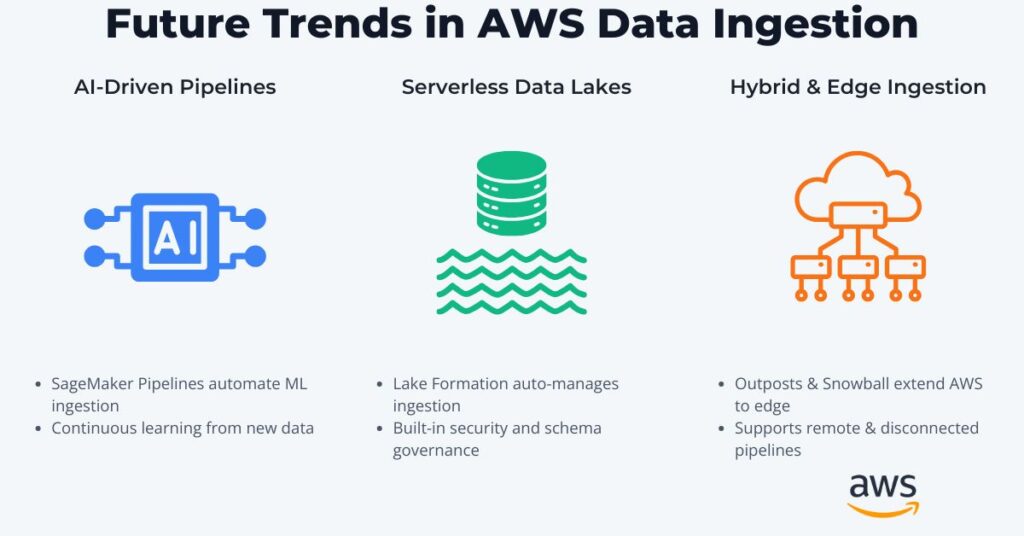
SageMaker AWS ML offering includes SageMaker Pipelines that automate the end-to-end ML workflow. This also includes ingestion and preprocessing, reducing manual effort. They also have built-in monitoring and retraining triggers, making them continuous learning pipelines responding to data drift or performance degradations. They seamlessly integrate with AWS ingestion tools like Glue and S3 that can feed directly into SageMaker. SageMaker can consume its output for data for real-time or batch model training.
Serverless data lake ingestion reduces the need to manage infrastructure. Here, AWS Lake formation automates data movement in S3-based data lakes. It also supports fine-grained access control and schema management for addressing security requirements for data ingestion. Therefore, Lake Formation seamlessly integrates with Glue, Athena, and Redshift Spectrum, enabling seamless querying and analytics upon ingested data.
Cloud computing, while a powerful paradigm, is never the solution for every type of problem. Hence, hybrid solutions provide the necessary flexibility to address a wide range of applications. As mentioned, hybrid solutions effectively augment data ingestion pipelines, addressing latency and other challenges. To maintain consistent ingestion pipelines then AWS Outposts is a good solution that extends AWS services to on-premises environments.
Ingestion pipelines may need to collect data from remote and disconnected sources. AWS Snowball provides bulk data transfer that supports these pipelines.
Conclusion
Automated data ingestion in AWS eliminates manual data handling and reduces errors for high-volume ingestion workflows. Therefore, this improves the efficiency and accuracy of data ingestion workflows. It also leverages integrated AWS services to enable highly scalable, real-time analytics. These services include Glue, Kinesis, and S3.
Automated data collection and ingestion in AWS enhance analytic workflows through an integrated pipeline with minimal manual intervention. They achieve this by streamlining data flow from diverse sources into a centralized storage, and this enables faster access and analysis. Also, they improve pipeline reliability, reduce delays, and ensure consistent data is available for downstream applications.
It is now time to explore these key AWS services like Glue, Kinesis, and Lake Formation. They will allow you to build robust and automated data pipelines. You will also need to implement best practices to utilize them for scalability, security, and cost efficiency. Thereby, you will unlock the full potential of your data workflows.
Further Reading: Recommended Books on AWS Data Ingestion and Cloud Data Engineering
For those looking to explore AWS data pipelines, ingestion tools, and cloud-based ETL workflows in more depth, the following books are highly recommended:
- “Data Engineering with AWS” by Gareth Eagar
- “Streaming Data: Understanding the Real-Time Pipeline” by Andrew G. Psaltis
- “Designing Data-Intensive Applications” by Martin Kleppmann
- “AWS for Solutions Architects” by Saurabh Shrivastava
Affiliate Disclaimer
As an Amazon Associate, AI Cloud Data Pulse earns from qualifying purchases. This supports our content at no additional cost to you.
References
- AWS Glue Documentation – https://docs.aws.amazon.com/glue
- Amazon Kinesis Data Streams – https://docs.aws.amazon.com/kinesis
- AWS Lambda Documentation – https://docs.aws.amazon.com/lambda
- Amazon S3 Documentation – https://docs.aws.amazon.com/s3
- AWS Lake Formation – https://docs.aws.amazon.com/lake-formation
- AWS IAM Best Practices – https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html
- AWS CloudWatch – https://docs.aws.amazon.com/cloudwatch
- AWS Glue Schema Registry – https://docs.aws.amazon.com/glue/latest/dg/schema-registry.html