
1. Introduction: How Apache Spark for Big Data Analytics is Driving Innovation
Apache Spark for big data analytics has solidified itself as one of the leading frameworks for building large-scale data processors. Many industries have adopted it for its role in enhancing real-time analytics. It is a flexible data processing framework that also accelerates machine learning workflows. This article surveys Apache Spark’s architecture, benefits, and the applications developers have built using its framework. Our goal is for our readers to acquire an appreciation of Apache Spark’s role in the big data revolution.
2. The Architecture of Apache Spark for Big Data Analytics
2.1 How Apache Spark’s Data Processing Framework Works
The big data processing generic paradigm distributes processing across many parallel workers to meet its processing demand. Subsequently, the intent behind building Apache Spark was to allow developers to build applications that process data across distributed clusters for scalability. This framework’s unique feature is that its applications can utilize in-memory computation that accelerates analytics. The key building blocks of its framework are drivers, executors, and cluster managers. It also supports constructing Directed Acyclic Graphs (DAGs) that streamline task scheduling. These elements make the Spark framework a powerful big-data analytics tool.

For a more in-depth breakdown of Apache Spark’s internal components, such as RDDs, DAG execution, and cluster management, refer to our Apache Spark Architecture: Big Data Guide.
2.2 Core Components of Apache Spark for Big Data Analytics
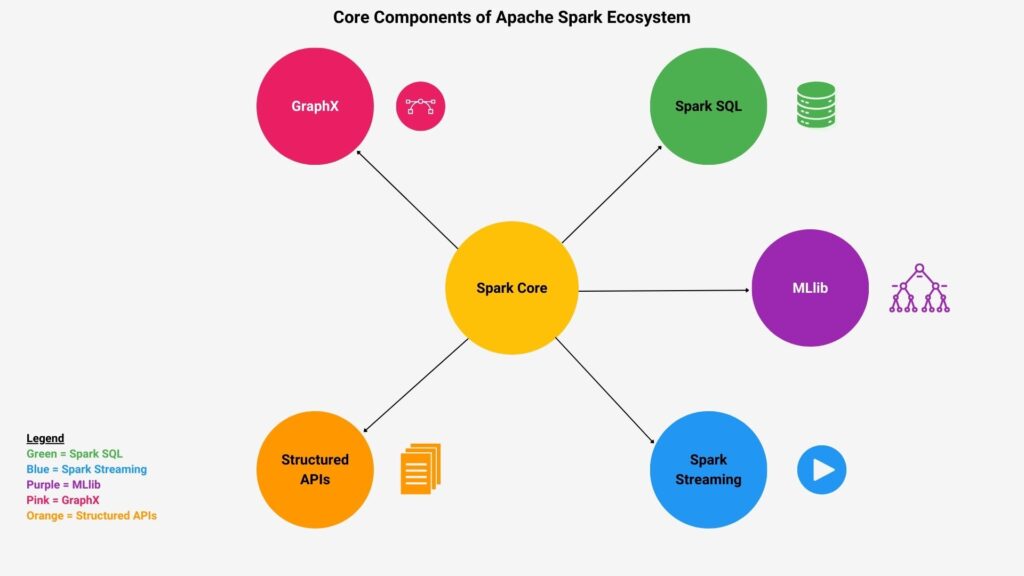
Spark consists of many components developers can use to build big data analytic applications. However, several core components invariably comprise these applications. Spark’s core intent is to allow distributed processing to scale applications depending on their workload. Therefore, Spark Core is the key component because it will enable applications to perform distributed task execution across datasets. Spark-based applications primarily work with datasets. Therefore, Spark SQL is a key component because it processes structured data with SQL-like queries. These include formats like Parquet, Avro, and JSON.
Another growing area is real-time analytics, which Spark Streaming components support. Developers are increasingly building machine learning applications on Spark, and MLlib provides many algorithms to allow them to make these applications at scale. These algorithms include but are not limited to, classification, regression, clustering, and collaborative filtering. Another important consideration with big data is how it is presented to human users, often in graphs. GraphX is a tool that powers graph data analytics with the Spark ecosystem.
2.3 Cluster Management in Apache Spark’s Data Processing Framework
We must also consider which environments to which we can deploy Spark-based applications, including YARN, Kubernetes, and Mesos. Other options include AWS Glue. Spark is based upon the horizontal scaling of resources to achieve processing throughput. This is apparent because its resource allocation adjusts dynamically based on workloads. Environments that effectively perform distributed task management will improve cluster efficiency and effectiveness. Also, effective cluster management will enhance Spark’s big data capabilities. Kubernetes has the advantage of automated cluster scaling for optimal performance. Mesos provides general-purpose resource management and is highly scalable. However, Hadoop is only scalable for Hadoop workloads, limiting it to Hadoop jobs.
2.4 How Apache Spark Integrates with Big Data Ecosystems
We also want to consider this because Spark’s design intent is to perform analytics on vast datasets. Spark integrates with diverse data storage systems, making it versatile for big data environments. These include object storage, NoSQL storage, and real-time streaming environments. Object storage systems include Hadoop HDFS, Amazon S3, and Azure Data Lake. Whereas NoSQL storage includes Cassandra and MongoDB. An example of streaming is Apache Kafka. Also, Spark supports multiple data schemas, including Parquet, Avro, and JSON.
2.5 Fault Tolerance and Scalability in Apache Spark for Big Data Analytics
Spark’s main strength is horizontal scalability, which adds more nodes when data volume increases. This guarantees real-time analytics by expanding clusters. Having distributed nodes and clusters also helps with fault recovery, along with distributed storage, which addresses data loss risks. Spark includes the Resilient Distributed Dataset (RDD), a dependency graph that records all transformations. This allows Spark to efficiently recompute lost data partitions in the event of failure. This resilience supports large-scale analytics applications built on the Spark framework.
3. Key Benefits of Apache Spark for Big Data Analytics
3.1 Speed and Efficiency in Apache Spark’s Data Processing Framework
We will now consider some of Spark’s unique advantages. Spark accelerates data processing and transformation through in-memory processing, which enables it to process data 100x faster than Hadoop in some cases. It also utilizes parallel task execution, which reduces latency across distributed nodes. Spark also performs efficient data caching that optimizes big data analytics workflow. These advantages result in quick insights and faster decisions and are well-suited for real-time environments.
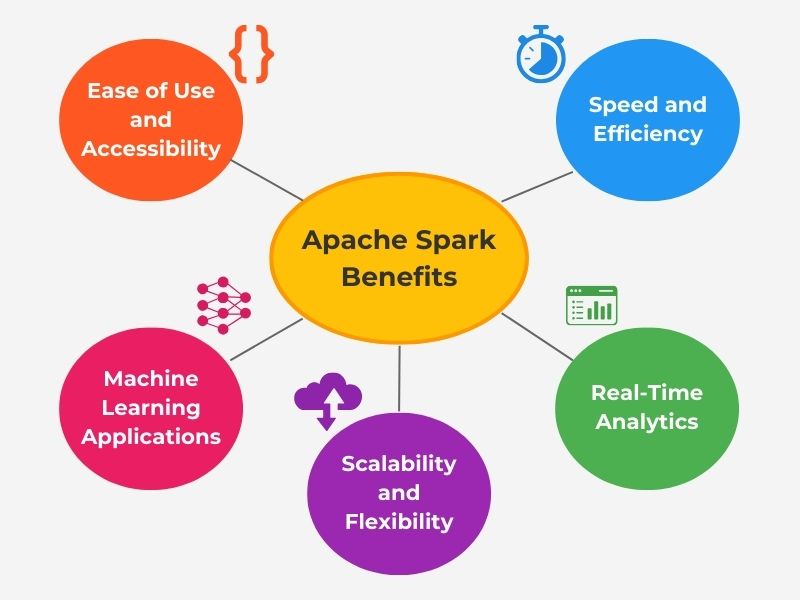
3.2 Real-Time Analytics with Apache Spark for Big Data
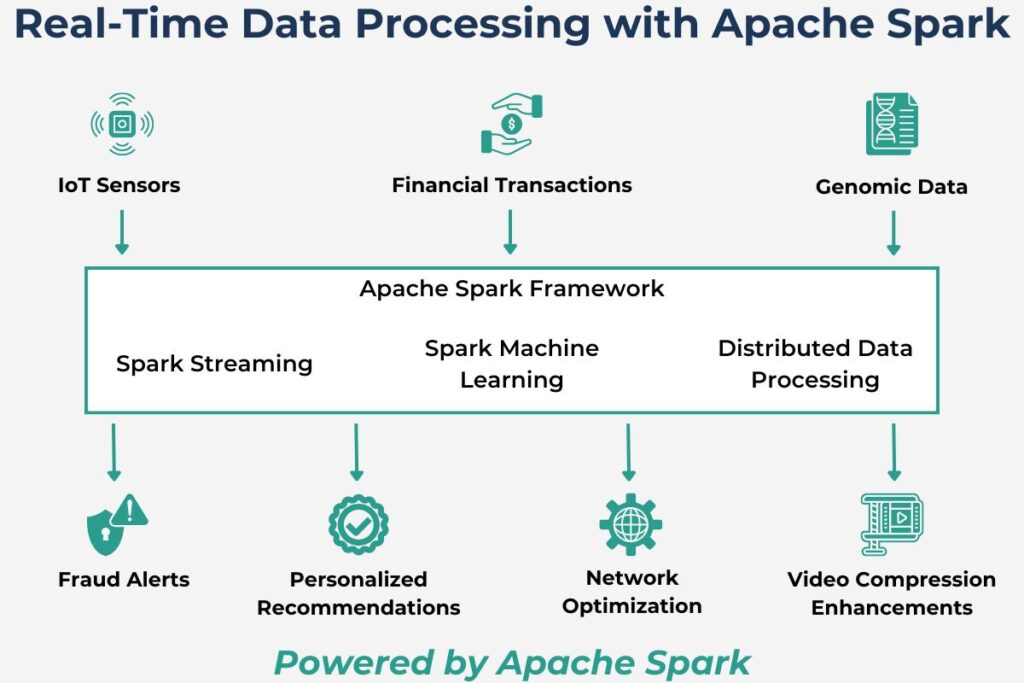
Spark’s main strength is real-time processing, unlike other big data tools that are more batch-processing-focused. It supports real-time analysis through Spark Streaming, which processes live data feeds. This allows it to support time-sensitive applications like fraud detection and IoT-related applications. This helps to bridge the gap between batch and stream processing. Also, instant insights provided by Spark Streaming enable proactive business decisions.

3.3 Scalability and Flexibility of Apache Spark for Big Data Analytics
We must implement effective scalability to meet the increasing demands for processing vast datasets. Spark can scale across petabytes of data by adding cluster nodes and provides dynamic resource management to ensure smooth operation. This flexibility is essential for machine learning, streaming, graph analysis, and other large dataset processing applications. Also, Spark can adapt to cloud environments for scalable deployment. This scalability allows Spark to meet the demands of large organizations.
3.4 Machine Learning Applications with Apache Spark
Machine learning is gaining more prominence within the large data processing ecosphere. Therefore, suitable frameworks are necessary to meet this processing demand. Apache Spark provides MLlib, allowing machine learning applications to scale efficiently with large datasets. This trains models on massive datasets faster than traditional tools. Spark’s distributed data process further enhances AI development pipelines. Additionally, Spark supports integration with deep learning frameworks like TensorFlow and PyTorch. This supports many industries, including finance, healthcare, and retail.
3.5 Ease of Use and Accessibility in Apache Spark for Big Data Analytics
Alongside its performance, its ease of use with developers and accessibility are equally important. Spark’s APIs support various languages, including Python, Scala, Java, and R. This allows developers to pick and choose depending on their needs and skill sets. Developers can also use Spark SQL to perform structure data queries on various file types, including Parquet, Avro, and JSON. PySpark is a Python framework that simplifies machine learning and data science workflow. Another advantage for developers is that Spark integrates with popular IDEs and Jupyter notebooks, allowing developers to build code iteratively. These user-friendly interfaces lower the barrier for developers building big data analytics applications.
4. Real-world applications of Apache Spark for Big Data Analytics
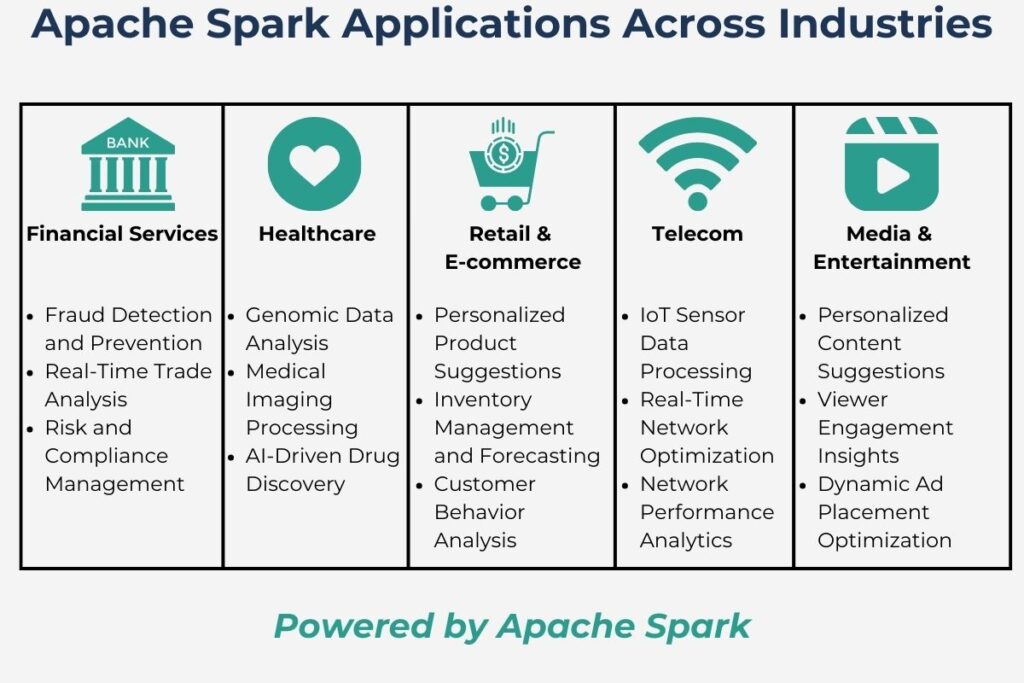
4.1 Financial Services: Apache Spark for Real-Time Analytics
Many financial applications are suitable for implementation in Apache Spark, especially those handling real-time data. Many banks currently implement fraud detection and compliance monitoring in Spark because of the high volume of real-time data. The framework can also implement trade analysis applications that require real-time analytics. Risk assessment often requires an instant response while processing large data volumes, making it an ideal candidate for implementation in Spark. Transactional data is another application that needs instant insights, for which Spark is a prime choice. While portfolio management does not need real-time insights, Spark is still a valuable platform for AI-driven analytics.
Learn how big data in financial services transforms real-time analytics, fraud detection, and trade analysis in our article, Big Data in Financial Services: The Big Data Revolution.
4.2 Healthcare Innovations: Apache Spark Machine Learning Applications
While Spark’s architecture is directed to data streaming, it has powerful ML capabilities. Many healthcare applications use machine learning to deliver value, often performed in real time. Spark’s distributed machine learning benefits genomic sequencing, while drug discovery pipelines can leverage Spark’s ML capabilities. Another important healthcare activity is medical imaging, which Spark-based applications can process at scale. Also, Spark-based healthcare analytic software can power personalized treatment plans. Nonmachine learning applications are patient monitoring systems that use Spark Streaming for real-time alerts.
Explore how big data in healthcare drives advancements in genomic sequencing, medical imaging, and personalized treatment in our blog, Big Data in Healthcare: Transforming Patient Care.
4.3 Retail and E-commerce: Apache Spark for Big Data Analytics
Retail and e-commerce companies must process large real-time datasets for rapid response. They must respond nearly instantaneously to customer behavior, and Spark is a prime candidate to build applications that personalize recommendations. With just-in-time inventory, inventory forecasting, and supply chain logistics, companies must process large datasets in real time. Spark provides real-time analytics for inventory forecasting while optimizing supply chain logistics. Nimble retailers must also detect sales trends from millions of transactions quicker than their competitors. Spark enables real-time detection of these trends, allowing rapid response. Targeted marketing is fluid in many scenarios and must change rapidly. Therefore, Spark’s real-time capabilities can build customer segmentation models, allowing for more rapid and improved target marketing.
Discover how big data in retail enhances customer personalization, inventory forecasting, and targeted marketing in our article, Big Data in Retail: Revolutionizing the Shopping Experience,
4.4 Telecommunications and IoT: Real-Time Analytics with Apache Spark
With increasing input data, industrial and operational systems must process and respond in real-time. This is especially true for systems incorporating IoT sensors. Spark Streaming is well suited for IoT sensors that stream data for real-time analysis. Telecom networks have extensive traffic data and must continually optimize based on that data in real-time. Spark is an ideal choice here, given its real-time processing capabilities. Similarly, power networks must also be optimized, but, more importantly, they need to predict outages with more reliability. Here, Spark can improve outage prediction with real-time environment data. Both power and telecommunication networks can utilize Spark’s machine-learning capabilities to analyze and improve network performance. Also, they and other infrastructures use these capabilities to build predictive maintenance models to improve efficiency.
Learn how big data in smart cities revolutionizes urban life through IoT and real-time analytics in our blog, Big Data in Smart Cities: Improving Urban Life Through Data Analytics.
4.5 Media and Entertainment: Apache Spark Data Processing Framework
Media and entertainment must respond to a more demanding audience, again in real time. Both personalized content recommendations and audience targeting can leverage Spark’s real-time analytics. Analyzing viewer engagement is another crucial activity for media companies where Spark-based applications can provide meaningful insights. Spark’s data pipelines are applicable for ad placement optimization. While analyzing viewer behavior is essential, delivering quality video to customers is also crucial. Streaming media companies can use Spark to enhance video compression and delivery workflows.
5.1 Optimizing Performance in Apache Spark’s Data Processing Framework
Spark’s fundamental ethos is performance, which is never guaranteed unless the platform is fine-tuned. Invariably, the first consideration is caching frequently accessed data or persisting it to avoid unnecessarily recalculating it. This is one of the fundamental tenets of computer science and engineering since its inception. Data shuffling between nodes can adversely affect performance, and practical strategies are necessary to minimize this.
These include optimizing partitioning and join strategies. Configuration tuning matching workload requirements is another dimension for optimal performance, including executor memory, cores, and parallelism.
We must consider optimizing data handling because Spark works with large data volumes. Data warehousing technologies optimize data analysis by storing data in columnar rather than the traditional row format. This provides distinct advantages when you only need to access a subset of columns or filter and read a single field. This is well suited to many of the analytic algorithms that utilize Spark, and storing data in formats like Parquet or ORC will speed up query performance and reduce disk I/O. Data transfer is another potential bottleneck, and utilizing fast serialization formats like Kryo can accelerate data transfer and task execution.
5.2 Scaling Apache Spark for Real-Time Analytics
Another aspect of Spark is its ability to scale in real time, but intelligent scaling strategies must be employed to utilize this powerful feature fully. Spark provides dynamic resource allocation that allows scaling the platform in response to changing workloads. It is advisable to take advantage of this feature in such scenarios. Good data partitioning strategies are needed to ensure that data is evenly distributed across partitions to avoid stragglers that slow down processing. The emergence of cloud services, including AWS EMR, Databricks, and GCP, provides automatic scaling of Spark clusters to match data volumes.

These services abstract the need to scale clusters from developers manually. Although Spark clusters handle real-time data streams, micro-batching strategies still play a role in preventing overwhelming clusters. Spark also achieves its performance through tasks distributed across clusters, and it is necessary to ensure that these are correctly balanced.
5.3 Cost Optimization for Apache Spark Clusters
All applications have budget constraints, and since clusters can scale, their running costs can also increase. To avoid cost overruns, adopting cost-optimization practices is essential.
Most cloud environments provide spot instances, which can reduce costs by up to 90%. The Spark platform can mitigate the disadvantages of spot instances, such as their termination by cloud operators at short notice.
Idle clusters are an unnecessary expense. Implementing scripts to shut down idle clusters automatically is a sound practice. Similarly, resizing clusters during non-peak hours to match lower demand helps save resources and cut costs.
Configuring executors to balance memory and CPU usage optimally can also achieve cost efficiency. Another effective strategy is selecting the proper data storage medium. Solutions like AWS S3 or Azure Blob Storage offer significant savings for data with low access needs.
Finally, consider opportunities to compress data. Data compression can further reduce storage costs, making it a valuable addition to your cost-optimization strategy.
5.4 Ensuring Security in Apache Spark for Big Data
We can never ignore security considerations because bad actors seek to corrupt our data to produce erroneous results and insights. Of course, there are other harmful consequences whenever bad actors have access to our data or systems. We must protect data when we store and transmit it. We achieve this through proper data encryption at rest and during transmission.
Another essential principle is to allow access to Spark resources only when it is needed, following the principle of least privilege. Therefore, we implement Role-Based Access Control (RBAC), limiting access to these resources using user roles and permissions. Closely related to this is authentication to ensure users are who they say they are. Several authentication tools exist, including Kerberos, OAuth, and SSL.
We can also enhance data security by isolating workloads from each other where they cannot access each other. This is especially important should one workload get compromised so that the other workloads are not at risk of getting compromised. We can isolate Spark workloads deployed to the public cloud through Virtual Private Clouds (VPCs). These isolate resources in one VPC from those in another VPC.
Security is never set up and forgotten, and we must continually evaluate existing security implementation and practices. We achieve this by conducting regular security assessments and applying patches that address vulnerabilities that arise in Spark clusters.
5.5 Monitoring and Debugging Apache Spark Workloads
We can initially optimize our Spark clusters for data processing most efficiently. However, we cannot guarantee that they will remain optimal, and their performance may drift over time. We can use Spark UI to monitor job performance both initially and continuously. This also allows us to identify bottlenecks and track task execution.
Like all other computing systems, we must set up logging and metrics with alerts. These will enable us to detect issues in real time and troubleshoot them. At the same time, alerts will notify teams of job failures or cluster anomalies. Another essential tool set is job profiling tools. These allow us to analyze and debug slow-running jobs for performance improvements.
It is also important to track resource utilization (i.e., CPU, memory, disk) to prevent overload and optimize performance.
6. Conclusion: The Future of Apache Spark for Big Data Analytics
When applied to big data analytics, Apache Spark will continue to shape industries. Its inbuilt versatility for real-time analytics and machine learning drives innovation. Its scalability also supports handling the increasing volume of global data. Future developments in Spark will only enhance AI and IoT applications. Therefore, Apache Spark will remain the leading solution for advanced data processing frameworks. As explored in our blog, Explore Big Data Revolution. Apache Spark embodies the transformative power of the big data revolution, driving innovation and scalability across industries.
Further Reading: Apache Spark for Big Data Analytics
Here are some highly recommended books for deepening your understanding of Apache Spark:
- Learning Spark: A Beginner’s Guide to Big Data Analytics
- Spark: The Definitive Guide to Mastering Big Data Processing
- High Performance Spark: Tips for Optimizing Big Data Workflows
- Advanced Analytics with Spark: Patterns for Big Data Insights
- Big Data Analytics with Spark: A Practical Guide for Professionals
Disclaimer: This post contains affiliate links. If you make a purchase through these links, we may earn a commission at no extra cost to you. Thank you for supporting our content!
References
- Apache Spark Official Website
The official homepage of Apache Spark, where readers can learn about Spark’s architecture, components, and latest updates. - Databricks Documentation
Comprehensive documentation for Databricks, a platform built on Apache Spark, featuring tutorials and advanced resources for developers. - Apache Spark on AWS
A detailed guide to running Apache Spark on Amazon EMR, useful for those interested in cloud-based big data processing. - Apache Spark Streaming Guide
Official documentation for Spark Streaming, a critical component for real-time analytics. - What is Spark – Apache Spark Tutorial for Beginners
A beginner-friendly introduction to Spark’s architecture and components, hosted by DataFlair, a trusted educational platform for big data technologies.