
Introduction
Google originally designed the Apache Spark architecture for distributed and scalable big data processing, utilizing parallel processing architectures. It consists of several core component types, including the driver, executors, cluster manager, and execution engine. Spark application designers and developers need to be able to optimize their applications for efficiency. Therefore, they should understand Apache Spark architecture in big data to build applications with optimal processing efficiency. This guide provides a tutorial on the architectural components, execution model, and data abstraction with a focus on optimization techniques. It will also provide an Apache Spark diagram for a visual explanation of its architecture and execution flow.
1. Core Components of Apache Spark Architecture in Big Data
To better understand the Apache Spark Architecture, it is essential to understand the core components and how they cooperate with one another.
1.1 Driver Program in Apache Spark Architecture
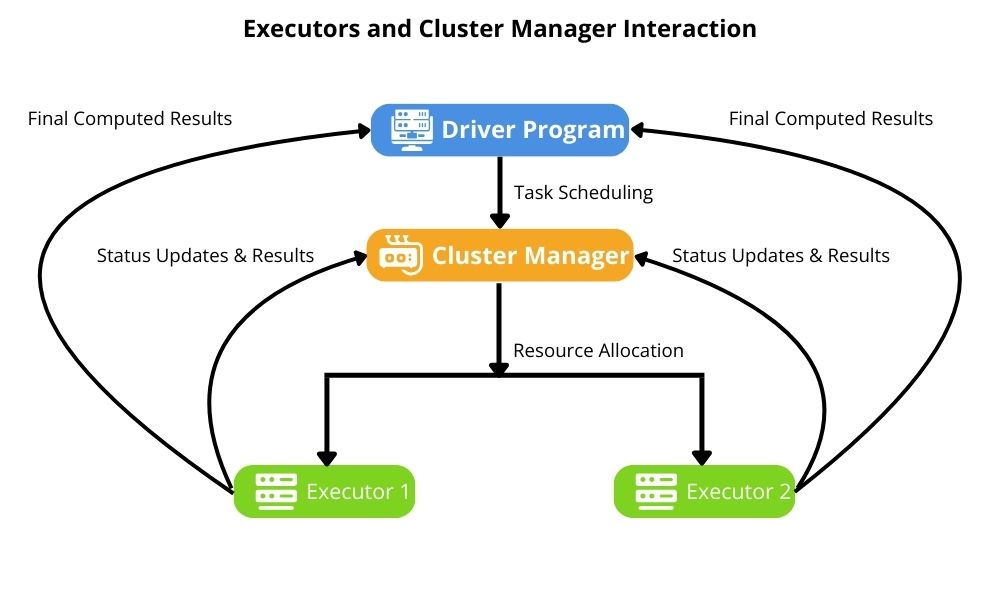
Any framework built around parallel and distributed processing still needs a central processor that orchestrates all the other processors. A good analogy is the conductor of the orchestra, hence the term orchestration. In the case of Spark, this is the driver program that acts as the Spark application’s central coordinator. Its main function is to translate user commands into tasks for execution across a cluster. It also holds the Spark Context used to initialize the Spark environment. Along with these functions, it monitors task execution and collects results from distribution computations. Application developers should note that properly optimizing the driver is essential in ensuring efficient resource allocation and fault recovery.

Understanding Spark’s role in the broader big data ecosystem helps developers see its advantages over traditional processing frameworks. Read our in-depth analysis in Explore Big Data Revolution.
1.2 Executors: How They Process Big Data in Apache Spark
Executors are the workhorse of our Spark applications. They run tasks that the driver assigns to them and process the data in parallel. They have their own memory and CPU resources needed for high-performance execution. When they are performing their processing tasks, they store intermediate computation data to enhance Spark’s processing speed. They also communicate with the driver to return computed results. They only live for the duration of the Spark job that owns them and terminate upon completion of that Spark job. This ensures the freeing up of cluster resources.
1.3 Cluster Manager
Because Spark applications run on parallel and distributed processors, it follows that we need to allocate resources to these applications. The cluster manager’s job is to allocate resources for all the Spark components within the distributed environment. There are several implementations, including YARN, Mesos, and Spark’s built-in standalone mode. They are responsible for ensuring optimal resource distribution across executors. Application developers should ensure proper cluster manager configuration to prevent bottlenecks during processing. Cluster managers are also responsible for enabling Spark’s processors to scale efficiently for big data applications.
For a foundational understanding of various big data frameworks and how Apache Spark’s cluster management compares to others, check out our Beginner’s Big Data Guide: Understand, Collect, Analyze.
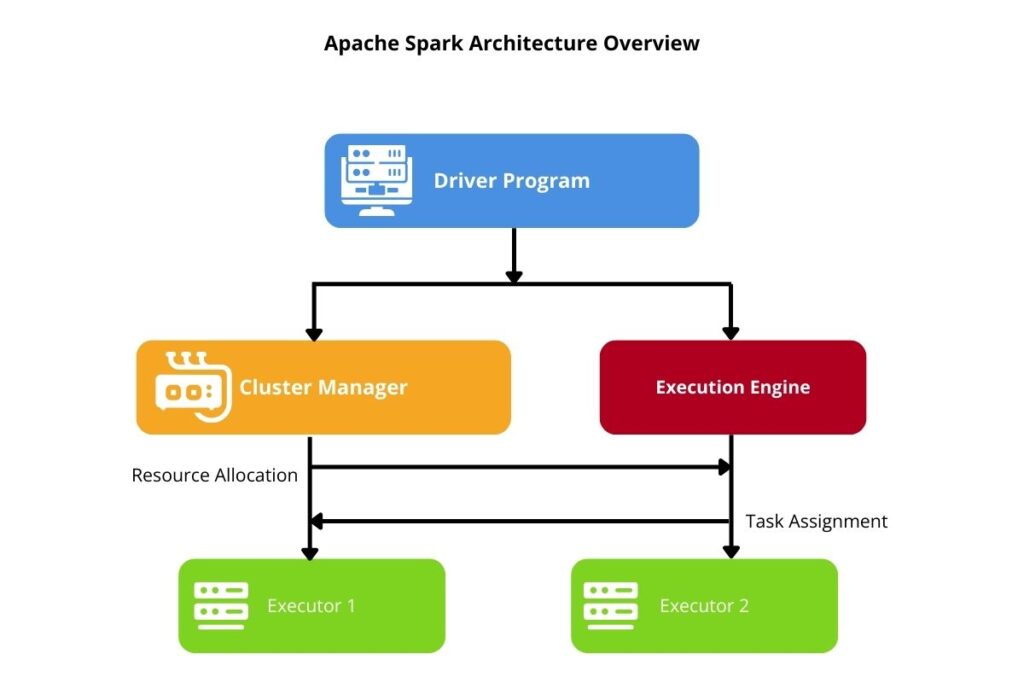
1.4 Execution Engine
Whereas the driver is the overall task orchestrator, it is the execution engine’s job to schedule and run tasks using an optimized pipeline. To utilize a distributed processing environment, the execution engine must subdivide jobs into small stages for parallel execution. To achieve efficient processing, the engine leverages Direct Acyclic Graphs (DAGs) to schedule and run tasks. It also continually adjusts resource allocation to balance workloads during the course of job execution. This component is crucial whenever applications are run for big data processing.
To further enhance performance, developers should focus on optimizing data partitioning, memory allocation, and DAG scheduling. For a deeper dive into best practices, check out our article on Optimizing Spark Performance and Speed.
1.5 Apache Spark Diagram: Visualizing the Architecture
Any textual description can only go so far in communicating the architecture. An Apache Spark diagram can further reveal the interaction between the driver, executors, and cluster manager. It is better able to visualize how tasks and data flow through Spark components. Also, a DAG diagram can showcase the Spark job’s executing workflow. Developers who understand the diagram can better debug and tune performance. Diagrams effectively complement text in providing a clear explanation of Spark’s architecture.
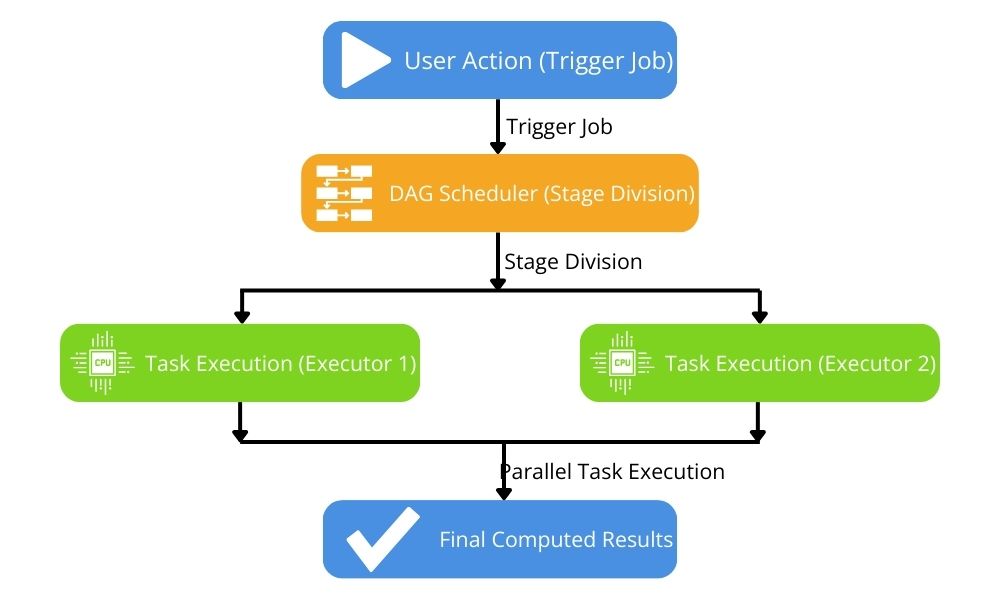
2. Apache Spark Execution Model in Big Data Processing
2.1 Job Execution Process
Spark jobs usually process data in a Resilient Distributed Dataset (RDD) or distributed, tabular data structure (Dataframe). Triggering an action on these data structures causes a Spark job to commence. Each job performs a series of transformations on the input dataset. The relationship between these transformations (transformation dependencies) is the basis of how a job is split into stages. Each stage is then divided into multiple parallel tasks executed across the cluster, leveraging the power of distributed processing. The execution model that defines how a Spark job is executed will optimize Spark performance for big data workloads. Therefore, it is crucial to properly understand execution flow to enhance tuning and perform troubleshooting effectively.
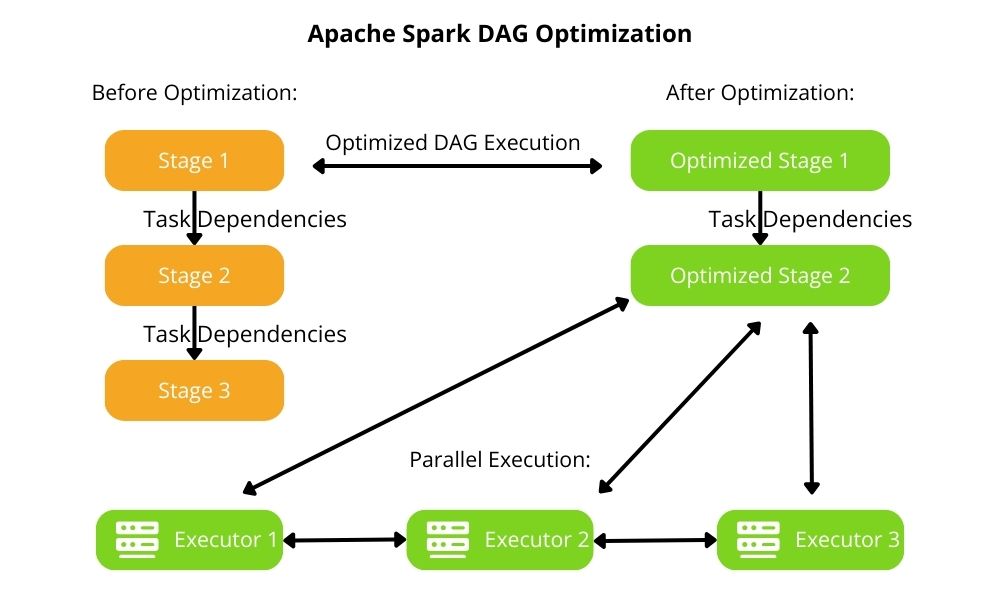
2.2 Directed Acyclic Graph (DAG) Optimization
Spark must properly divide a Spark job into stages based on the transformations it must perform. To achieve this, Spark represents the transformations in an execution model. It does this by analyzing the transformations and generating a DAG that represents the execution model. The DAG consists of stages processed sequentially, whereas each stage consists of tasks executed in parallel. Spark also performs DAG optimization to minimize redundant computations for faster execution.
Spark executes tasks in parallel. It also prevents tasks within a stage from executing until completion of task execution in the prior stage. Therefore, Spark must ensure an efficient task execution order. The DAG scheduler is responsible for this.
DAGs play a pivotal role in efficient Spark processing. Therefore, a clear DAG structure is essential for efficient resource utilization.
2.3 Task Scheduling and Execution
Executors are responsible for executing Spark jobs, and the task scheduler assigns jobs to these executors based on available resources. The executors execute the tasks comprising the Spark job stages in parallel to maximize cluster efficiency by leveraging distributed processing. Slow-running tasks can create bottlenecks, slowing down the whole job. A technique that addresses these bottlenecks is launching duplicate (speculative) copies on different nodes and using the fastest result. This helps to prevent these straggler tasks from delaying job competition. The name of this technique is speculative execution.
Data shuffling between nodes also introduces latency to a Spark job. Task locality optimization is a technique that reduces unnecessary data shuffling. It achieves this by scheduling tasks on nodes where the required data is already present.
The task scheduler uses these techniques to improve task scheduling efficiency, which enhances overall Apache Spark performance.
2.4 Fault Tolerance Mechanisms
Processing failure can result in the whole batch job failing, and it is necessary to restart the job. This means that the time the failed job took is lost, costing both time and money. For jobs handling RDDs, the logical chain of the transformations is stored as transformation history in Spark. Another name for this stored transformation history is RDD lineage. Whenever there is a failure, then Spark can recompute lost data by tracing it back to its source.
Another fault tolerance technique is checkpointing. This saves or takes a snapshot of an RDD that is a result of a particular transformation within the transformation chain. Spark saves this RDD to a reliable storage location (e.g., HDFS). Therefore, should the next subsequent stage fail, then the job can simply roll back to the last save RDD that becomes the new starting point. Consequently, it enhances fault recovery by breaking lineage dependencies.
Apache Spark also has the sophistication to perform automatic retries. This helps to stop failures from disrupting overall job execution.
Fault tolerance is a key reason for selecting the Spark framework over other frameworks.
2.5 Data Shuffling and Partitioning in Big Data
Apache Spark’s primary advantage is leveraging distributed processing to reduce job execution time. Data partitioning is utilized to support distribution processing where data is distributed across partitions. However, this potentially introduces overheads, where the job must often shift data between partitions during execution. This is better known as data shuffling, which redistributes data between partitions, introducing latency. This impacts performance and resource consumption.
This makes it necessary to introduce partition optimization strategies that reduce data shuffling to minimize latency and processing time. To better optimize partitioning, Spark should uniformly distribute data across nodes. Hash partitioning is one technique that helps achieve this. Therefore, effective partitioning strategies enhance the efficiency of Apache Spark architecture.
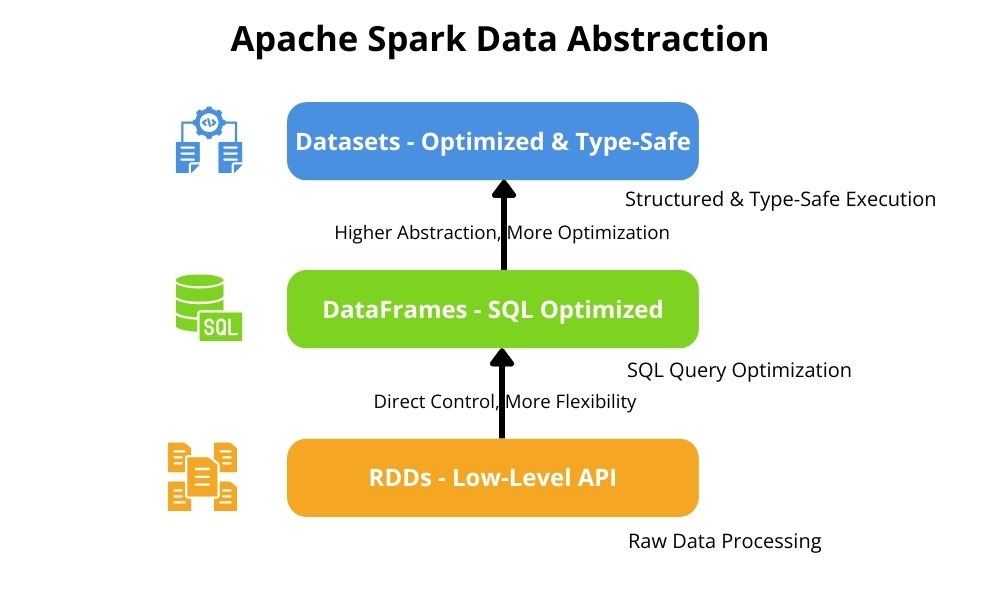
3. Data Abstractions in Apache Spark for Big Data
A critical Spark architecture component is data abstraction that Spark-based applications process. Spark’s very purpose is the efficient transformation and processing of that data and deriving insights for critical decision-making.
3.1 Resilient Distributed Datasets (RDDs)
Spark’s main advantage is leveraging distributed processing and organization data to map across distributed processors is paramount. Therefore, Resilient Distributed Datasets partition data into immutable, distributed data collections. This allows the processing of these collections in parallel, including fault tolerance. This easily supports common transformations applied to these collections, including map, filter, and reduce. Partition data in collections make them a size that allows in-memory caching, resulting in quicker analytics. This makes RDDs the foundation data structure for the Spark architecture. Another benefit is that RDDs provide flexibility for low-level data manipulation.
3.2 DataFrames
Structured data is more straightforward to analyze than unstructured data. Data organized as DataFrames represent structured data with named columns similar to data warehousing best practices. Applications operating on DataFrames can use Spark SQL’s Catalyst engine, which provides optimizations when querying DataFrames. DataFrames also allow in-memory analytics, allowing for greater efficiencies. They also simplify development since they support SQL-querying for big data analysis. Therefore, they improve performance over raw RDDs.
Another valuable advantage of DataFrames is that they integrate well with machine learning frameworks like TensorFlow. This makes DataFrames a powerful choice for AI-driven big data analysis. Learn more about leveraging TensorFlow for big data in our guide: How to Use TensorFlow for Big Data Analysis: A Beginner’s Guide.
3.3 Datasets
Both RDDs and DataFrames need data error runtime handling to prevent execution failure. Data error checking at compile time reduces code complexity and potential troubleshooting due to failure. Datasets can be as efficient as DataFrames due to Tungsten optimizations but may introduce serialization overhead if not used efficiently. These overheads include Java serialization and garbage collection overhead.
Dataframes outperform Datasets for pure query performance, given that Catalyst can optimize them more aggressively. However, Datasets offer type safety, potentially saving time and resources due to execution failures. They also enable compile-time checking, making code less complex.
Tungsten optimization is a set of performance enhancements for both DataFrames and Datasets, improving efficiency through whole-stage code generation, binary processing, and off-heap memory allocation. These optimizations enhance memory management, code generation, and CPU efficiency, making Spark applications faster and more efficient.
Datasets are ideal for strongly typed big data and integrate seamlessly with Java and Scala. Scala’s support of immutable data types makes it native to parallel processing.
3.4 Comparison: RDDs vs. DataFrames vs. Datasets
These different data representations each support different big data categories that Spark-based applications must handle. Hence, data type selection is a critical aspect of designing and building big data applications running on Spark. Each has its own set of advantages.
RDDs provide raw data control but at the expense of built-in optimizations and are ideally suited to unstructured or semi-structured data. Many big data solutions must handle such data and need to make fine-grained transformations or low-level data manipulation. Also, they support fault tolerance and in-memory caching without schema enforcement.
When incoming data is structured, then DataFrames is a better choice. They enable efficient structure query processing and simply the queries needed to extract meaningful information from that data.
Ideally, Datasets are the first choice for structured data since they offer type safety and work with Java and Scala. Also, they are the best choice when performing business logic on structured data. However, when greater efficiency is needed, and complex business logic is less critical, it is better to utilize DataFrames. Also, Datasets are not supported by Python, which is another key consideration.
When optimizing Spark applications, it is necessary to carefully select the data abstraction that best suits incoming data and use cases. A good understanding of data abstraction differences is critical to best leveraging Apache Spark architecture.
3.5 Apache Spark Storage Formats
The efficient operation of Spark applications also depends on data storage, enabling efficient data retrieval for queries, transformations, and processing. The formats that will allow efficient writing to and reading from storage are Parquet, Avro, and ORC. Parquet and ORC provide columnar storage that allows for faster queries; columnar storage is the choice for data warehousing.
The selection of these formats depends upon their particular use cases. Avro is great for streaming workloads and long-term storage due to its efficient schema evolution. Therefore, it integrates well with Kafka and Spark Streaming. ORC is highly optimized for Hive and Hadoop but has a higher metadata overhead. Parquet is better suited for cloud-based.
Also, utilizing compression techniques allows storage optimization, thereby reducing storage costs. Since they reduce data size, they speed up data retrieval, improving query execution. This is because decompression is in-memory, which performs better than transferring larger data items to and from storage.
Reducing I/O overhead becomes critical for big data workloads, making data format selection critical. Therefore, storage format selection will impact Apache Spark architecture efficiency.
Conclusion
Apache Spark architecture is a powerful framework for big data processing, with its modular design supporting high-performance distributed computing. Spark’s execution models, such as DAGs and task scheduling, optimize performance. Additionally, understanding Spark’s data abstractions is crucial for building scalable applications. Finally, a well-structured Apache Spark diagram enhances comprehension of its architecture.
Further Reading
Disclosure: Some of the links below are affiliate links. This means that if you click on a link and make a purchase, we may receive a commission at no additional cost to you. Our recommendations are based on expertise and relevance to the topic.
- High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark by Holden Karau & Rachel Warren
- Learning Spark: Lightning-Fast Big Data Analysis by Jules S. Damji, Brooke Wenig, Tathagata Das & Denny Lee
- Spark: The Definitive Guide: Big Data Processing Made Simple by Bill Chambers & Matei Zaharia
References
- Apache Spark Official Documentation
- Apache Spark™ Under the Hood – Databricks eBook
- Spark Applications Explained – Databricks Glossary
- Performance Analysis and Auto-tuning for SPARK in-memory analytics – IEEE Xplore