1. SageMaker Pipeline Workshop: An Introduction to ML Automation
If you find building and deploying learning models overwhelming, then you should read this SageMaker Pipeline Workshop. For an overview of AWS SageMaker please look at SageMaker Overview for ML Engineers: A Practical Guide to Amazon’s ML Platform.
SageMaker Pipelines automate ML workflows by removing manual configuration at each stage and their integration. It allows ML engineers to configure automated ML workflows, reducing effort in building ML pipelines. They also enable engineers to leverage AWS services to support these pipelines easily.
There are other substantial benefits from automating ML workflows besides saving engineers time and effort. It also reduces manual intervention and errors, thereby improving efficiency. Automated ML workflows automate data processing and model training, resulting in improved scalability. This also leads to faster experimentation and deployment. Because SageMaker Pipelines streamline ML processes, resulting in faster experimentation, deployment, and better resource allocation.
Readers will benefit from this SageMaker Pipeline Workshop. They will acquire an understanding of SageMaker Pipelines and their key benefits. Readers will learn how to choose SageMaker Pipelines over other traditional ML Pipelines. Next they will follow a step-by-step guide in building a SageMaker Pipeline. Readers will also familiarize themselves with the best practices around SageMaker Pipelines, along with challenges and limitations. Finally, they will discover future trends in ML pipelines.
2. Understanding SageMaker Pipelines
Developing ML models involves several key activities, such as data preprocessing, ML model training, evaluation, and deployment. Data preprocessing is usually needed for raw data used to train the model. Training and evaluating model performance are done iteratively, refining the model until its outputs are within the accepted ranges. Deployment involves hosting the model where it provides insights and predictions from real-world data. Several deployment options are available, including SageMaker Endpoints, batch processing, and inference pipelines.
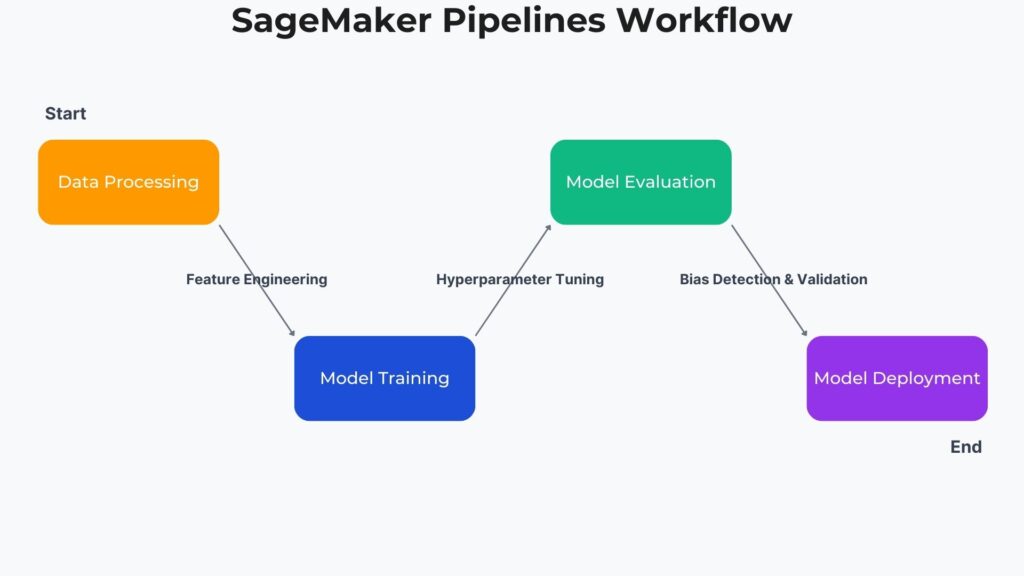
Automating and orchestrating these activities improves the efficiency of ML model development by significantly reducing the manual effort. Amazon SageMaker Pipelines are an AWS-native ML workflow orchestration tool that automates data preprocessing, model training, evaluation, and deployment. It also provides end-to-end automation of these activities, allowing integration of these stages.
This also covers other key benefits that Amazon SageMaker Pipelines provides. It enables scalability, where engineers can deploy complex models and models that handle large datasets. SageMaker pipelines introduce model versioning similar to software versioning where engineers can track model development and rollback to earlier versions. Since it reduces manual intervention, engineers can utilize CI/CD for ML models, allowing for more incremental development. One of the key advantages covered in this SageMaker Pipeline workshop over other ML workflow automation tools is its seamless integration with AWS Services. These services include AWS S3, SageMaker Feature Store, Model Registry, AWS Lambda, and Step Functions.
3. Why Use SageMaker for ML Pipeline Automation?
Traditional ML Pipelines pose several challenges including manual effort needed to perform feature engineering, model selection, and hyperparameter tuning. Feature engineering involves modifying specific input data fields to remove discrepancies, giving the model a false interpretation of the data. Different models are suited to different use cases, e.g., image recognition over text interpretation. Selecting the model that fits the use case is essential for it to make correct predictions and insights from real-world data. It is crucial also to adjust the model’s hyperparameters when training. Incorrect hyperparameters can lead to the model’s transfer function following well known erroneous behaviors, e.g., overfitting or underfitting.
Traditional ML Pipelines also lack version control, allowing engineers to reproduce earlier experiments or rollback to earlier models. Not following best practices adopted in the software engineering field made ML model development very sporadic and unpredictable.
The other challenge was deploying ML models at scale. This is similar when engineers manually installed software on different machines. This was a cumbersome and error-prone activity.
SageMaker Pipelines addresses these challenges where it automates model training and retraining. Engineers can automate feature engineering for training and input data, reducing the prohibitive effort in this activity. Automated AWS ML workflows utilize tools like SageMaker Autopilot and Bayesian optimization to automate hyperparameter tuning. They can also identify and select models that best fit the use case for these ML models.
SageMaker Pipelines seamlessly integrate with AWS Services allowing them to leverage these services optimally.
To enable engineers to reproduce experiments, SageMaker Pipelines maintain a model registry. This manages early models and their versions that engineers can access for performing experiments.
These pipelines are also event driven allowing for real-time updates. An example is new data arriving in S3 automatically triggering model retraining.
4. Step-by-Step Guide: Building a SageMaker Pipeline Workshop
This is the SageMaker workshop core section detailing building a model training pipeline utilizing AWS ML automation. For further details around SageMaker pipelines, the reader is encouraged to check Amazon SageMaker Pipelines.
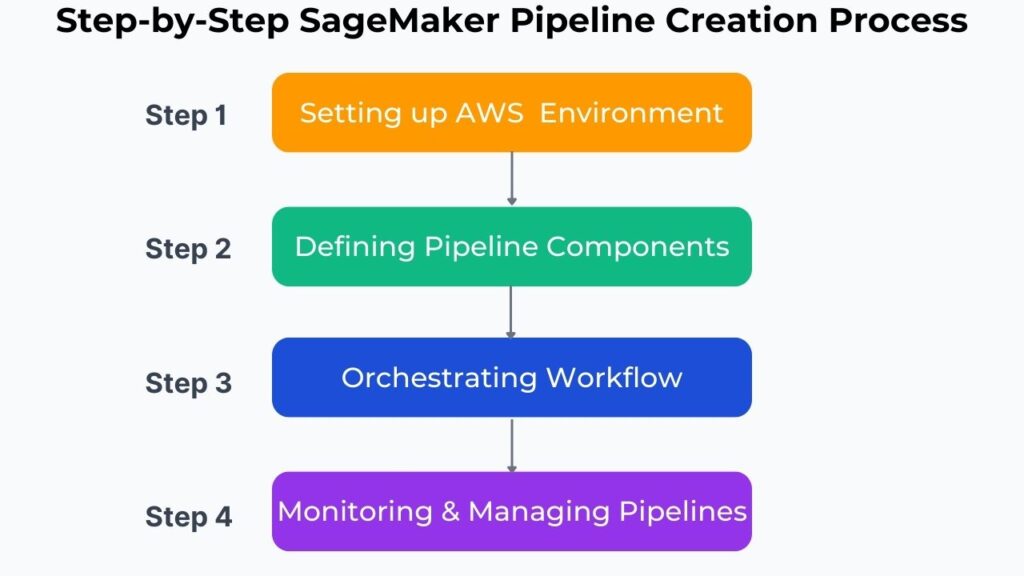
Step 1: Setting up the AWS Environment
We will assume that the engineer already has an AWS account. However, there are several services that engineers need to build an automated ML pipeline. As a minimum, they need to configure SageMaker Studio and an S3 bucket for dataset storage. SageMaker Studio provides a visual that allows engineers to visually design pipelines without writing configuration code. Writing configuration code for automated processes is tedious, demanding, and error-prone. Therefore, the ability to visually design automated ML pipelines is essential. S3 buckets are ideal for storing datasets used to train ML models given their cost and accessibility. SageMaker Pipelines’ seamless integration with S3 buckets further improves their accessibility and organization.
Step 2: Defining the Pipeline Components
Most ML pipelines consist of the following components:
- Data Preprocessing
- Model Training
- Model Evaluation
- Model Deployment
Data Preprocessing
Raw real-world data is rarely clean and normalized for ML models to process correctly. There are several operations that engineers must perform on raw datasets for ML models to handle them properly. Engineers can set up SageMaker Processing Jobs for each preprocessing operation, and there are many data preprocessing operations. The more important ones include data cleaning, feature engineering, feature scaling, data encoding, and data splitting. Other vital activities include data transformation, data augmentation, dimensionality reduction, data imputation, and outlier detection and removal.
Model Training
Model training is what differentiates ML models from other information processing models. Most information processing models operate from a prepared set of instructions that the model executes. However, ML models are trained with expected input and output patterns and modify their training weights accordingly. Hence model training is the central part of ML model development.
ML Engineers use SageMaker Estimator to train their models, an API that manages infrastructure, data input, and training configurations. Engineers can visually interact with it through SageMaker Studio, thereby simplifying training ML models on AWS. Estimators execute training jobs on AWS and support distributed training and built-in algorithms, leveraging seamless integration with AWS. They also enable automatic model deployment upon training completion.
Model Evaluation
ML model evaluation is the equivalent to software unit and systems testing. This is especially important for bias detection and drift in ML models. Here the SageMaker Clarify service detects bias in datasets and ML models. Meanwhile, SageMaker Model Monitor tracks model performance in production. These tools help ML engineers ensure fairness, accuracy, and data integrity, and also integrate with SageMaker Pipelines for continuous monitoring. Engineers can also continually optimize model performance through these tools.
Model Deployment
In the past, engineers created models with no proper versioning, making it impossible to replicate any testing. SageMaker Model Registry integrates with S3 to store model artifacts and versioned model files. It manages and tracks these registered models, metadata, and approval statuses. It integrates with SageMaker Pipelines to manage versioned models upon training completion and access these models for deployment.
Step 3: Orchestrating the Workflow
SageMaker Pipelines enable ML engineers to automate ML model training workflows. They can visually create a workflow definition for SageMaker Pipelines through SageMaker Studio. SageMaker Studio provides Pipeline Graph UI where developers can define, modify, and monitor Workflows through a drag-and-drop style graphical interface. SageMaker also provides developers pre-built components where they can define steps within the pipeline without writing extensive code.
Engineers can execute the pipelines either through boto3 or AWS SDK.
Step 4: Monitoring and Managing Pipelines
SageMaker Studio also provides a pipeline execution dashboard where ML engineers can monitor pipeline execution. It displays each step’s dependencies, statuses, and logs to engineers. All operations are persisted to CloudWatch logs allowing engineers to perform any debugging needed.
5. Best Practices for SageMaker Pipelines
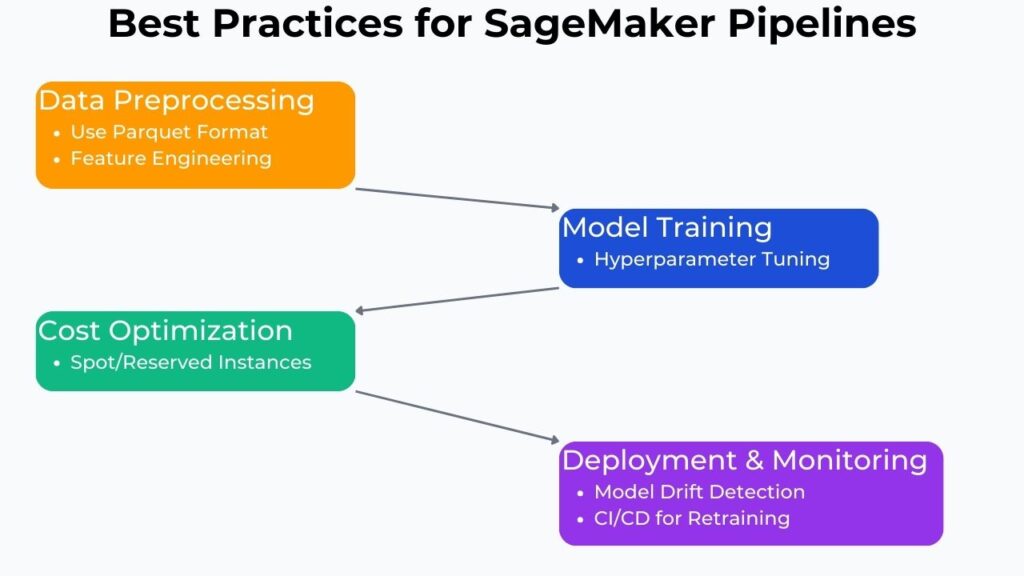
This SageMaker Pipeline workshop will also provide SageMaker best practices for optimizing SageMaker Pipelines. Since data preprocessing is the first stage in ML model development, then it is essential to optimize data processing. For many uses, data storage in Parquet format provides the best performance, mainly because it stores data in columnar format. The main benefit is that this reduces I/O operations and improves query format.
Hyperparameter tuning when done manually is often time-consuming and error-prone. Making it the main bottleneck for any machine learning effort. SageMaker Autopilot automates this hyperparameter tuning, reducing the main impediment to efficient machine learning. It does this through Bayesian optimization and running multiple training jobs.
Continual environmental changes will cause ML models deployed as inference engines to drift and require retraining. Engineers can use SageMaker Model Monitor to monitor inference engines to detect drift, allowing them to decide whether to retrain these models.
Engineers can also automate retraining based on SageMaker Model Monitor outputs through Lambda and EventBridge. Further leveraging SageMaker’s integration with AWS.
AWS ML cost optimization is also essential and engineers can optimize instance selection and pipeline scheduling for efficient cost optimization. Some examples are selecting Spot Instances or Reserved Instances. Spot instances provide extensive and substantial cost savings for any non-critical workloads. Whereas Reserved Instances offer considerable cost savings for stable workloads.
6. Challenges and Limitations
In our SageMaker Pipeline workshop, we have guided the reader in setting up SageMaker Pipelines, including some best practices. However, this workshop is incomplete if it fails to address various challenges and limitations associated with SageMaker Pipelines.
While we have guided engineers in building pipelines, there is still a steep learning curve for AWS newcomers. Acquiring knowledge in AWS services and architecture will better prepare engineers in working with SageMaker Pipeline.
Associated with training, deploying ML models as inference engines, are AWS ML costs, especially for large-scale ML workloads.
Because the ML model design is embedded within its weights, its operations are far less interpretable than conventional instruction-based code. This makes debugging ML pipelines much more difficult. And engineers need tools like CloudWatch logs and SageMaker Debugger to debug and troubleshoot ML models effectively.
Finally, engineers need to take into account pipeline execution time, which is dependent upon the compute resources available. Several optimization strategies exist, including distributed training for large models and selecting appropriate instance types (i.e., GPU vs CPU).
For further discussion around SageMaker Pipelines best practices, please refer to Best practices and design patterns for building machine learning workflows with Amazon SageMaker Pipelines.
7. Future Trends in ML: The Evolution of SageMaker Pipeline Workshop
This SageMaker Pipeline workshop guided readers through the current state of the art. However, it is worth considering the future of ML automation especially around SageMaker advancements and net-gen ML pipelines. Serverless ML pipelines introduce further elasticity and leveraging distributed processing. Increasing the use of Lambda-based ML pipelines could provide such benefits.
Federated learning integration can enable privacy-preserving ML pipelines. Regulatory authorities continually increase demands for privacy in the AI and Big Data processing.
SageMaker Studio already provides the ability to build pipelines visually, which can further enhance this through no-code ML pipeline capabilities. A fitting complement is generative AI and LLM integration to automate feature engineering and model tuning.
8. Conclusion
Our SafeMaker Pipeline workshop showed we need ML automation to reduce manual effort in building ML models. This is because manual effort is highly inefficient, error-prone, and unable to repeat experiments. It also encouraged reader to make their first pipeline to get hands-on experience building an ML automated pipeline. This workshop also helped readers understand AWS ML workflow best practices.
9. Further Reading on SageMaker Pipeline Workshop
Disclosure: This section contains affiliate links. If you purchase through these links, AI Cloud Data Pulse may earn a commission at no extra cost to you.
For those looking to expand their knowledge on SageMaker Pipelines, machine learning automation, and best practices, the following resources are highly recommended.
Books
Learn Amazon SageMaker: A Guide to Building, Training, and Deploying Machine Learning Models for Developers and Data Scientists by Julien Simon.
A comprehensive guide to mastering SageMaker’s features, covering hands-on implementation, automation, and ML deployment strategies.
Amazon SageMaker Best Practices: Proven Tips and Tricks to Build Successful Machine Learning Solutions on Amazon SageMaker by Sireesha Muppala, Randy DeFauw, and Shelbee Eigenbrode.
This book provides practical insights, optimization strategies, and real-world applications of SageMaker for ML workflows.
Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications by Chip Huyen.
A must-read book covering ML pipelines, deployment strategies, and model monitoring best practices.
External References
For official documentation and industry insights, refer to the following resources:
- Amazon SageMaker Pipelines Documentation – AWS official guide on SageMaker Pipelines, with detailed features and implementation guides.
- Best Practices and Design Patterns for SageMaker Pipelines – An AWS blog post discussing ML workflow automation best practices.
- AWS Machine Learning Services – Learn about AWS’s suite of ML services, including SageMaker.