
Introduction
We explored that Apache Spark has become the go-to solution for large-scale data processing. However, we must focus on optimizing Apache Spark performance to reap its benefits and maximize efficiency in data workflows. This article explores the techniques for boosting Spark’s speed and reducing execution time. We cover techniques ranging from simple configuration tweaks to data partitioning strategies. Our goal is that by the end of the article, you will have actionable insights on optimizing Apache Spark performance in your jobs.
Section 1: Fundamentals of Optimizing Apache Spark Performance
1.1 Understanding Spark’s Architecture
Implementing distributed data processing helps organizations effectively and efficiently process large, voluminous data sets. It is the basis of the Spark architecture, which includes the driver, executors, and cluster manager.
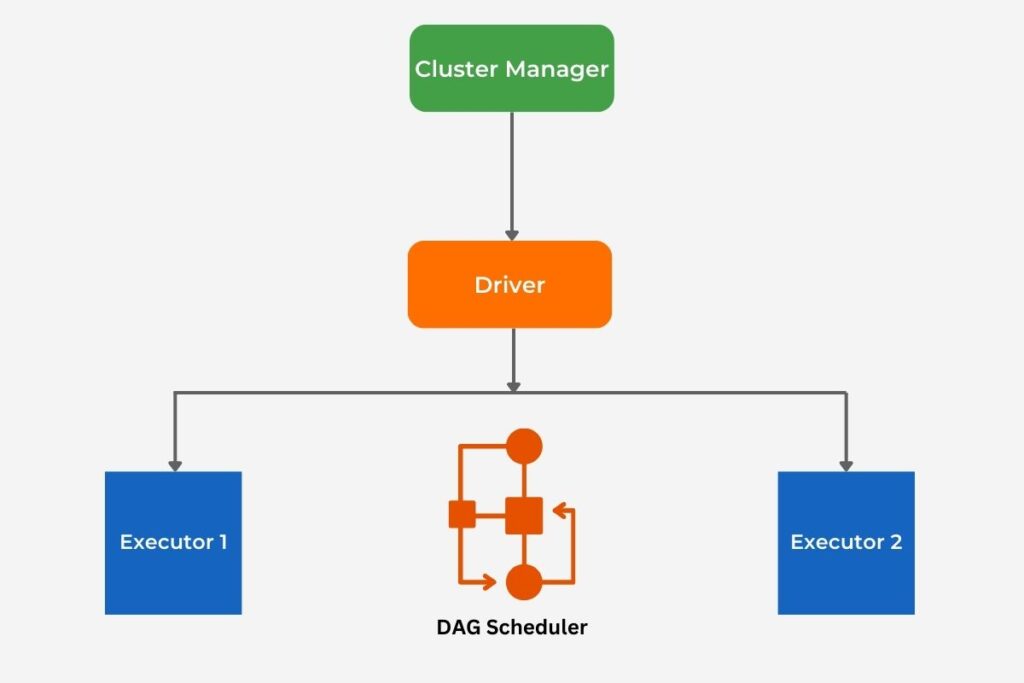
Also, to achieve and improve optimization, it is necessary to have a solid understanding of the distributed acyclic graph (DAG) scheduler. Read more in High Performance Spark. Resource allocation plays a key role in performance tuning, and knowing the execution model helps pinpoint inefficiencies.
1.2 Why Optimizing Apache Spark Performance is Essential
Saving time and computation resources is key to efficient big data processing, which explains the necessity of performance tuning. This ensures better resource utilization in clusters. Optimized jobs reduce costs in cloud-based Spark setups. In addition, faster Spark jobs mean quicker insights from data, helping to improve competitiveness. However, poorly tuned jobs can lead to failed executions.
1.3 Common Challenges in Optimizing Apache Spark Performance
An essential step towards performance optimization is identifying and removing common performance bottlenecks. These common bottlenecks include data skew, suboptimal partitioning, high garbage collection time, poorly written transformations, and network shuffling.

Data skewing can often slow job execution, while suboptimal partitioning can cause memory overflow issues. It is crucial to tune garbage collection since this can negatively impact executor performance. Attention to transformation code is necessary since poorly written code can increase runtime. It is also important to reduce network shuffling, which is responsible for significant slowdowns.
1.4 Setting Realistic Performance Goals
However, when tuning and optimizing, Spark does involve trade-offs. Therefore, setting realistic performance goals at the start is necessary. This begins with defining benchmarks based on specific job requirements. Subsequently, the next step is to identify acceptable runtime for Spark tasks. This will help to avoid over-optimization that negatively impacts scalability. The primary trade-offs are speed and resource usage, necessary for making realistic choices. However, making good initial trade-offs is insufficient because of changing requirements and environments. Therefore, regularly revisiting these goals and trade-offs due to the evolving requirements and environments is necessary.
1.5 Tools for Measuring Spark Performance
To be able to tune Spark systems regularly, it is necessary to monitor Spark performance and utilize the tools available for this. Spark provides a UI that monitors job progress to allow regular tuning of Spark performance. Refer to the official Apache Spark documentation for more details. Cluster monitoring is another critical activity for performance tuning. Subsequently, we must integrate tools like Ganglia that perform this. Another important activity is to leverage metrics from Datadog or Prometheus. Another tool is Spark event logs, which help debug performance issues. Whenever we encounter expensive transformations, job profiles can offer insights into their root causes.
Section 2: Configuration Tweaks for Optimizing Apache Spark Performance
A good start to optimizing performance is to look for low-hanging fruit, such as configuration tweaks. Often, several tweaks in combination can significantly improve performance, and we will consider some of them here. For a comprehensive guide on tuning Spark executors and memory management, consider reading Learning Spark, which offers practical insights into efficient Spark configurations.
2.1 Tuning Spark Executors and Memory
Spark executors are the workhorse of Spark processing, and we cannot ignore their tuning for performance. Memory, which is closely related to executors, is an essential consideration for performance. A prominent performance inhibitor is out-of-memory errors; their recovery results in wasted time. Also, when performing optimal caching, overheads arise from memory page swapping. We can achieve optimal caching by using memory fraction settings. It is also essential to correctly allocate overhead memory for non-data processing or overhead activities. We must balance the memory needed for overhead activities and the memory required for data processing.

Also, ensure that each executor has a sufficient number of cores. Allocating more cores than necessary results in resource waste and can limit the number of executors for deployments from a core pool. Along with overhead memory, we must configure driver memory correctly. Spark application management processes require driver memory, and we must budget for that. For additional details on Spark executor and memory tuning, refer to the official Apache Spark Documentation.
2.2 Optimizing Spark SQL Queries
As relational and other database types, a good practice is query optimization. Given their table-like structure with schema, Spark SQL queries should use DataFrames over RDDs. Many databases provide tools for analyzing query execution plans for query optimization. Spark provides the catalyst optimizer that allows developers to optimize Spark SQL query plans. When using joins, then applying broadcast variables when feasible will optimize these joins. Shuffling data wastes time, impacting performance. Therefore, good design involves working with co-located data sources to reduce shuffling. Also, data size will affect the time to read, and we should reduce this by column pruning and removing data that is not processed. For an in-depth exploration of Spark SQL query optimization techniques, refer to the article ‘Apache Spark Optimization Techniques for High-performance Data Processing‘ by Necati Demir, PhD.
2.3 Managing Data Partitions
Spark primarily works on data and distributes this across a cluster through partitioning. Therefore, even partition distribution is essential for balancing processing across all the processing nodes. Workloads change even during a single processing run, making existing partitions uneven. Therefore, we must coalesce and repartition to ensure data is partitioned evenly throughout the processing job.
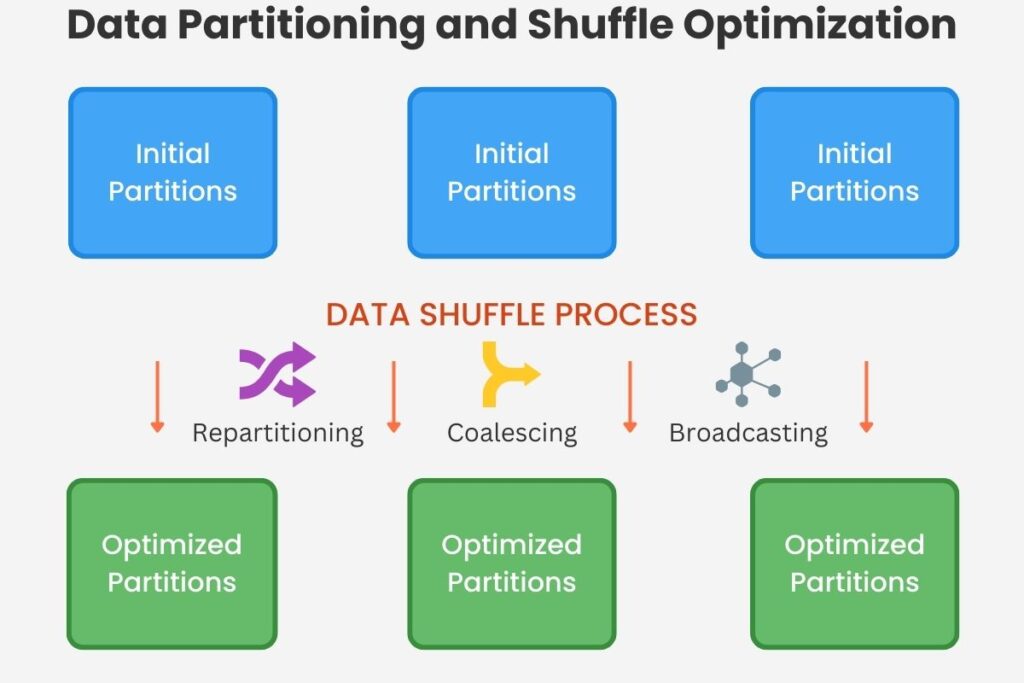
However, over-partitioning can slow down job execution due to inefficiencies from task scheduling overheads. Another consideration is memory size; we must monitor and adjust partition size to match memory size. Spark processing jobs can take advantage of repetitive queries through pre-defining partition keys. These organize data that allows efficient filtering, scanning, and processing.
2.4 Configuring Shuffle Behavior
Often, operations require redistributing the data across partitions. This is when they must perform aggregate operations, including joins, aggregation, and groupBy operations. Shuffling is the term applied to redistributing data across partitions, and we must continually adjust shuffle partitions for better distribution. Another technique to reduce shuffle data size is data compression. Also, we should optimize buffer sizes when writing and reading data to and from the disk due to disk I/O and network overhead. Also, we should follow good coding practices to avoid unnecessary shuffle operations. We should also monitor shuffle spills using Spark logs to identify and rectify their root causes. Refer to the AWS guide on Optimizing Shuffles for practical tips on shuffle optimization techniques.
2.5 Caching and Persistence Strategies
Overheads arise from caching and persisting data, and we should follow sound design principles to optimize these overheads. When performing iterative transformations, we must use caching. However, we must choose memory-only and memory-and-disk persistence wisely, balancing performance with cost. Similar to regular garbage collection, we should clear unused RDDs to free valuable memory. Since dataframes can consume a lot of memory, we should avoid caching them unnecessarily. Refer to the Spark documentation on RDD Persistence for further insights into caching and persistence strategies in Spark.
Section 3: Best Practices for Optimizing Apache Spark Performance
After considering quick wins, we now turn our attention to a set of best practices for optimizing performance.
3.1 Writing Efficient Transformations
Good coding practices elevate readability and correctness, enhancing coding quality. However, designing efficient transformation algorithms ensures the best utilization of computational resources. Several guidelines for transformation design will help improve efficiency and optimize the use of Spark resources.
Each additional transformation stage introduces additional overheads, slowing down processing. Therefore, we should combine multiple transformations into fewer stages wherever possible.
We covered wide transformations involving aggregate queries like groupByKey, reduceByKey, and join. However, as discussed earlier, these cause data shuffling that impedes performance. Therefore, reducing wide transformations wherever possible will reduce data shuffling and improve performance. Whenever you need to use groupByKey, consider using reduceByKey.
This command reduces data locally in each partition before shuffling, minimizing data transfer and memory usage and thereby improving performance.
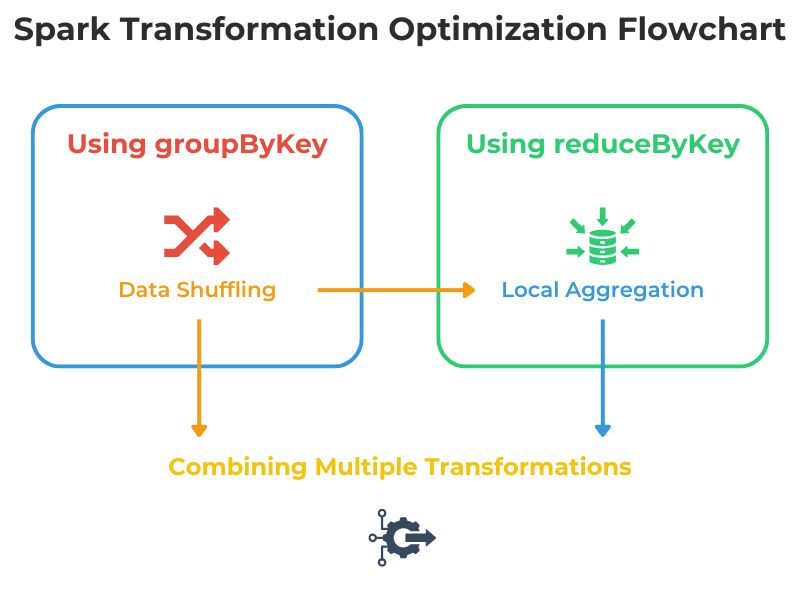
Other aggregate operations, like count and collect, require Spark to retrieve and process all the data. This potentially leads to out-of-memory errors and additional processing, which can impact performance.
Also, consider using the mapPartitions command instead of the map command. This processes data in batches per partition, thereby reducing function call overhead. In contrast to row-wise operations like map, this enables more efficient resource utilization and minimizes serialization/deserialization costs.
3.2 Leveraging Data Serialization
Data serialization is a significant overhead for big data processing, and efficient management is a key strategy for overall optimization. Kryo serialization is far more advanced than standard serializers provided by common language frameworks. It is an obvious choice when implementing serialization to achieve greater efficiency.

Additionally, different serializers impact performance in different ways, and we should test these when choosing our serializers.
Always ask the question of whether serialization is needed. If serializing complex objects is not required, then do not perform serializations. Since serialization imposes a significant performance cost, continuous monitoring is essential. This will allow us to identify opportunities to remove it to improve performance.
Beyond performance, memory space considerations, and we should always consider compressing serialization data when implementing transformations.
3.3 Efficient Data Input and Output for Optimizing Apache Spark Performance
A well-designed data transfer strategy will ensure good performance by following several guidelines. Columnar data storage is optimal for analytics, and choosing Parquet or ORC will optimize any transformations. Merging each output data file carries several overheads, and merging into larger rather than smaller files is better. Also, certain file formats are superior to others for specific workloads, and we should select the fitting format for transformations. Remember that batching is an important technique for many processing applications, and here, it will help minimize I/O operations that incur overhead. Finally, always explore caching opportunities whenever transformations involve data reuse.
3.4 Scheduling and Resource Management
We will reiterate the importance of always using dynamic resource allocation, leveraging Spark’s ability to balance usage. Another technique is scheduling jobs during low-peak cluster usage, making optimal use of processing resources. Resource contention is detrimental to job performance, and careful job planning is essential. We should always allocate enough cores per task wherever possible to ensure efficiency. Finally, test configurations in development environments to iterate your design before deploying to production. These are all common-sense best practices.
3.5 Continuous Monitoring and Feedback
Transformations do not operate in a static environment, and we must continually adapt them to changing inputs and requirements. We must constantly monitor their performance and check for both bottlenecks and unexpected errors. Spark UI enables the analysis of bottlenecks, while job logs provide insights into unexpected errors. We must also use metrics to track resource usage trends and adjust job parameters accordingly. Another crucial aspect is automating performance alerts based on performance data. This ensures a timely response to any performance degradations.
Section 4: Advanced Techniques for Optimizing Apache Spark Performance
However, more sophisticated techniques are available to optimize Spark’s performance, and we will review some of them here.
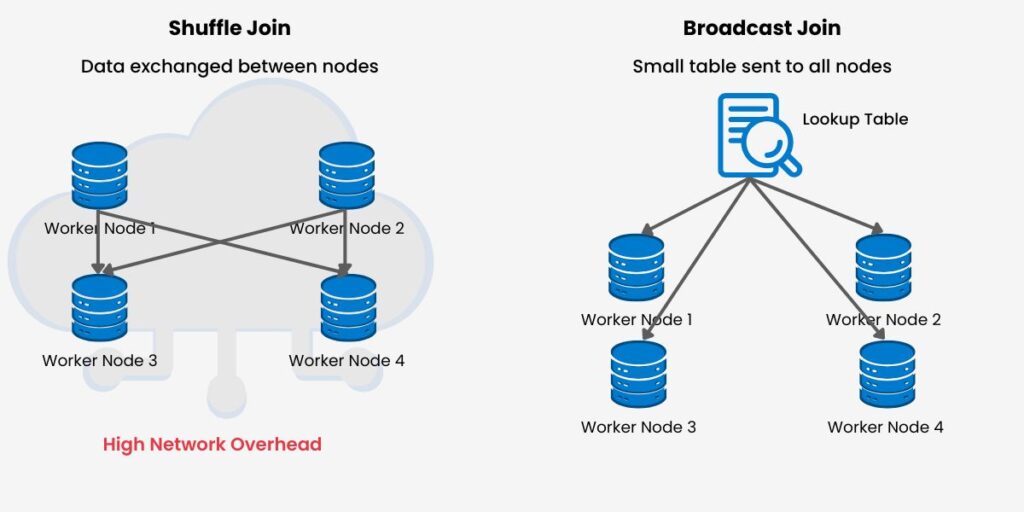
4.1 Using Broadcast Variables
Look-up tables are always handy for tweaking performance, and small look-up tables for faster joins will help optimize Spark jobs. Also, when we broadcast joins, we can reduce the shuffle operations that consume time and resources. However, we need to monitor broadcast sizes that lead to too much memory consumption, which causes out-of-memory errors to crash executors. Similarly, we must avoid broadcasting overly large datasets that cause out-of-memory errors and crash executors. Therefore, we must track broadcast usage, which we can do by leveraging Spark UI.
4.2 Custom Partitioning Strategies
Although Spark performs effective partitioning, specific use cases may demand optimal partitioning strategies that we must customize. Whenever there is uniform data distribution, hash partitioning will work well. However, despite its advantages, partitioning introduces overheads, and we also want to minimize these overheads in our jobs. Even though we arrive at custom strategies, we should validate these through tests that measure performance impact. Additionally, the cluster size will determine our partition count. For an in-depth guide on tuning partitioning strategies and optimizing Spark performance, High Performance Spark by Holden Karau and Rachel Warren provides valuable insights.
4.3 Dynamic Resource Allocation for Optimizing Apache Spark Performance
Cluster resource requirements continually change during each Spark processing job. Therefore, Spark resource allocation should respond to changing cluster needs during a job, and its dynamic allocation performs this. Enabling this will optimize cluster resources. Also, we want to avoid node underutilization by enabling dynamic allocation, optimizing partitioning, and adjusting task parallelism. Alongside setting these, we should monitor resource usage using Spark UI. Additionally, several Spark properties define resource scaling limits. These include number of executors, CPU core per executor, and memory per executor. We can also enable automatic scaling of executors and define scaling limits for dynamic allocations.
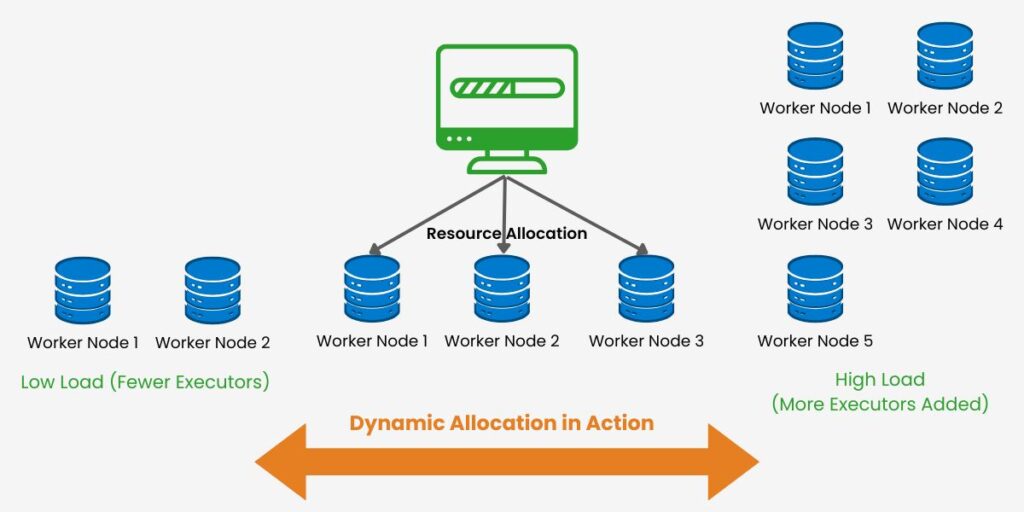
It is a good practice to continually monitor resource allocation during peak loads. Additionally, dynamic allocation thresholds should be fine-tuned based on job needs. See the Medium article on Spark Performance Tuning Best Practices for a deeper dive into performance tuning techniques, including best practices for resource allocation and optimization.
4.4 Working with Accumulators and Metrics
We can only control what we can measure, which applies to Spark’s performance. Accumulators are shared write-only variables to instrument our Spark jobs and track their metrics. However, overusing accumulators for critical logic can impede performance due to the overheads they introduce. Custom metrics are also helpful in assisting us when we have to debug transformations. However, we must monitor the accumulator’s impact on memory since they use memory resources required by the Spark job. We should also share insights gained from these metrics to optimize future jobs.
4.5 Exploring Spark Alternatives for Optimizing Apache Spark Performance
Spark is a powerful tool for many big data operations, but other tools are better suited for different use cases. Also, Spark is a generic framework, while other tools are better optimized and specialized for specific use cases. ETL workflows constitute a significant category of big data processing, and tools like Delta Lake are more specialized for this task. Presto is designed to perform interactive queries on Sparks data besides Spark jobs.
Spark uses micro batching to attain near real-time processing but is not an actual real-time processing engine. When real-time processing is required, we should leverage tools like Flink for low-latency, real-time applications. These include fraud detection and live monitoring, where every millisecond counts.
We should also consider combining Spark with tools that complement its abilities. Kafka is a data streaming tool that we can integrate with Spark to better stream data jobs. Spark is more generic, whereas Databricks, built on Spark, provides better usability and inbuilt security and integration.
Conclusion
We have provided a survey of both basic and advanced techniques for optimizing Apache Spark performance. We also demonstrate that proper tuning can dramatically improve job performance and execution speed. An equally important component is monitoring and continual feedback loops to maintain efficiency. Spark also provides tools we should leverage to ensure scalable and robust performance. We can fully realize Spark’s potential when we apply and continually tune the right strategies.
Further Reading
Affiliate Disclosure: The following book recommendations contain affiliate links. If you purchase through these links, we may earn a commission at no additional cost to you.
- High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark – Holden Karau & Rachel Warren
- Learning Spark: Lightning-Fast Data Analytics – Jules S. Damji, Brooke Wenig, Tathagata Das & Denny Lee
- Spark in Action – Jean-Georges Perrin
- Spark Performance Tuning Best Practices – Ashwin Kumar (2023, Medium)
References
- Apache Spark Documentation
- Apache Spark Optimization Techniques for High-performance Data Processing – Necati Demir, PhD
- Optimize Shuffles – AWS Documentation
- Spark Caching and Persistence – Apache Spark Documentation
- Comprehensive Guide to Optimize Data Workloads – Databricks