
Introduction: Unlocking TensorFlow’s Full Potential for Big Data Projects
Information technology’s rapid advance causes data generation to grow continually. Subsequently, this growth in data demands more advanced tools to process, analyze, and extract insights. Therefore, TensorFlow provides a robust framework with advanced techniques to optimize large dataset workflows. When businesses leverage TensorFlow techniques for big data, they can scale, automate, and enhance model performance across large datasets. This includes tools for feature engineering, hyperparameter tuning, and real-time data streaming. These techniques empower organizations to handle vast amounts of data with improved accuracy and scalability. This article explores how these techniques can unlock real-time insights, automate complex processes, and drive better results for real-world projects.
Section 1: Feature Engineering with TensorFlow Techniques for Big Data
1.1 Why Feature Engineering is Crucial: TensorFlow Techniques for Big Data
Often, large datasets contain raw data that is unstructured and meaningless. It is necessary to transform this data into meaningful inputs. Feature engineering is the technique that transforms raw data into meaningful inputs. A straightforward example of feature engineering is deriving insights from house data. The model can only derive meaningful insight when it has the age of each house. However, the raw data only contains the year they built each house. Developers can apply feature engineering to the raw data to calculate the age of each house using the year that builders built each house.
This demonstrates that properly engineered features will boost model accuracy and efficiency. Therefore, developers need feature engineering to bridge the gap between raw data and performance. However, it is necessary to automate this because datasets have many dimensions, making manual techniques highly time-consuming. TensorFlow provides tools that simplify applying feature engineering and make it automated to allow large-scale feature extraction.
This section explores TensorFlow’s most significant tools that aid developers with feature engineering.
1.2 TensorFlow Feature Engineering Tools
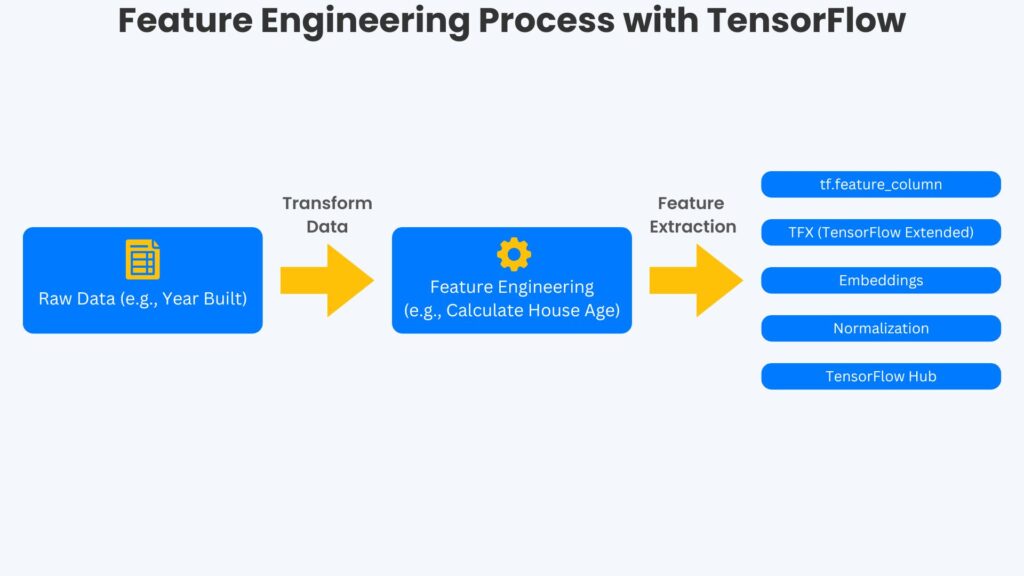
TensorFlow provides tools that aid feature engineers in transforming raw data into meaningful data. These tools include tf.feature_column, TensorFlow Extended, layer embedding, normalization, and TensorFlow Hub. The tf.feature_column allows the effortless transformation of structured data into usable features. The TensiorFlow Extended (TFX) will enable developers to automate feature pipelines for production environments. When categorical data is present, developers can build embedding layers to convert this data into dense representations. Different data fields are often unbalanced, and normalization techniques allow developers to balance feature distribution for model input. Pre-trained models are helpful for feature extraction, and TensorFlow Hub provides a catalog of these models that developers can reuse.
These ideas are also considered in Optimize TensorFlow Data Pipelines for Faster, Smarter Models. The figure below depicts the visual representation of the feature engineering process with TensorFlow. Highlighting key tools and the transformation of raw data (e.g., the year a house was built) into engineered features (e.g., the age of the house).
1.3 Managing Sparse and High-Dimensional Data
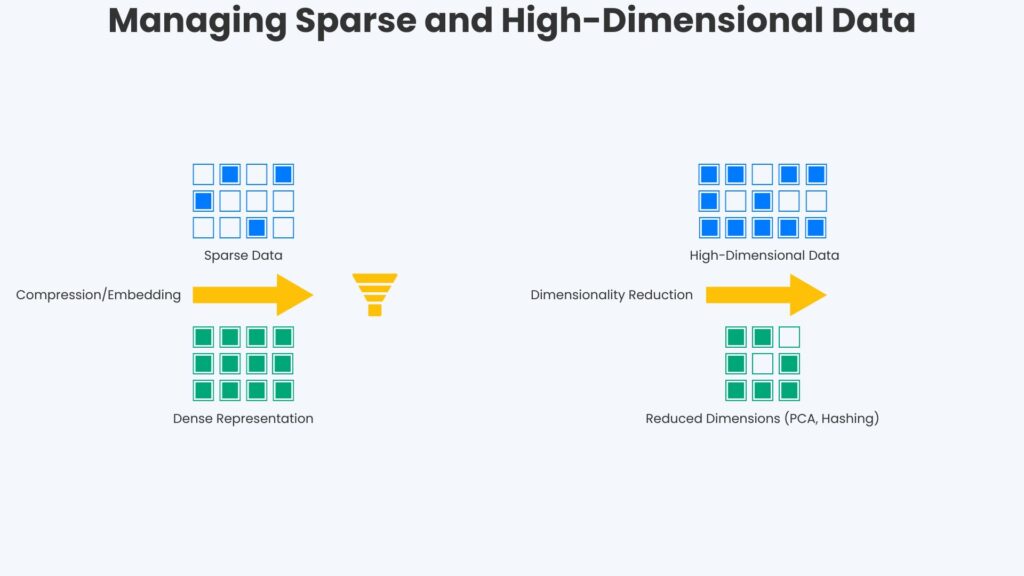
Another issue with raw data is sparseness, which has many dimensions that can affect training models. Often, raw data has many zero or missing values. Sparse tensors address this by only storing the zero elements and their corresponding indices. Therefore, sparse tensors reduce memory usage and computational overhead. Another technique addressing sparse data is embeddings that compress sparse data into dense format but still capture essential patterns.
Raw data often has many dimensions with insignificant overall variance. Principal Component Analysis (PCA) ranks these dimensions based on their variance and selects only the dimensions with the most variance. This reduces the dataset’s dimensionality but retains all the relevant information.
Another technique for both sparse data and many dimensions is feature hashing. A hash function processes each feature and assigns it to one of a fixed set of buckets. Multiple features may map to the same bucket, but the hash function ensures consistent mapping across the datasets. Feature hashing provides a fixed-length vector where each non-zero entry corresponds to the hashed feature. This addresses memory requirements and computational demands.
TensorFlow APIs provide these techniques for processing datasets with sparse data and many dimensions.
As illustrated in the figure below, sparse data can be efficiently represented using techniques like embeddings, which map sparse inputs to dense vectors. Similarly, high-dimensional data can be transformed into a lower-dimensional space while preserving essential information.
1.4 Automating Feature Pipelines with TFX: TensorFlow Techniques for Big Data
We have considered several feature engineering scenarios. However, we must automate and not perform our feature engineering stages manually. We must also integrate our feature engineering stages into our machine learning pipeline. TensorFlow provides TensorFlow Extended, which automates the different feature engineering workflows and allows integration into the machine learning pipeline. TFX also provides data validation that prevents erroneous features from entering the pipeline. It also supports feature transformation to ensure compatibility across datasets. Therefore, TFX simplifies deployment by standardizing the ML pipeline. TFX also supports real-time data processing that enables continuous model updates.
1.5 Feature Embedding for Categorical Data
Most ML models are neural networks; adding unique layers is another technique to reduce data dimensionality. These are embedding layers that reduce data dimensionality and produce dense vectures. These dense vectors enhance model accuracy. TensorFlow allows these embeddings to be learned during training. Another capability that TensorFlow allows is pre-trained embeddings that enable reuse for more rapid model development. TensorFlow provides embedding visualization tools where developers can interpret data relationships effectively.
Section 2: Real-Time Data Streaming with TensorFlow Techniques for Big Data
2.1 Importance of Real-Time Data Streaming
In many use cases, vast data processing must happen in real-time, and offline processing will not satisfy them. These use cases demand near-instantaneous insights, often to respond before competitors respond. One example is fraud detection, where damage can escalate quickly and needs a quick response. Therefore, transaction data must be processed in real time to alert users to any detected fraud. Hence, TensorFlow Techniques for Big Data include tools that enable high-frequency data ingestion. This allows immediate analytics that support operational efficiency across industries. Predictive maintenance is a key benefit that relies heavily on streaming data analysis. Real-time data also helps address the inherited lag in automated systems and responses.
2.2 Key Applications of TensorFlow Techniques for Big Data in Streaming
We already mentioned Fraud Detection, where we must process transaction data in real-time. Many other use cases demand vast data processing in real-time, and we consider a few here. Healthcare diagnostic use cases often demand real-time processing of live patient data and leverage TensorFlow. In retail, customer experiences happen in real time. Therefore, real-time processing is needed to personalize customer experiences. Smart cities have many use cases demanding vast real-time data processing. Traffic pattern analysis is one example that needs TensorFlow streaming models. Industrial IoT also has many use cases requiring data stream processing. Continuously monitoring equipment health is a prime example of processing real-time data streams.
2.3 Building Scalable Real-Time Pipelines with TensorFlow
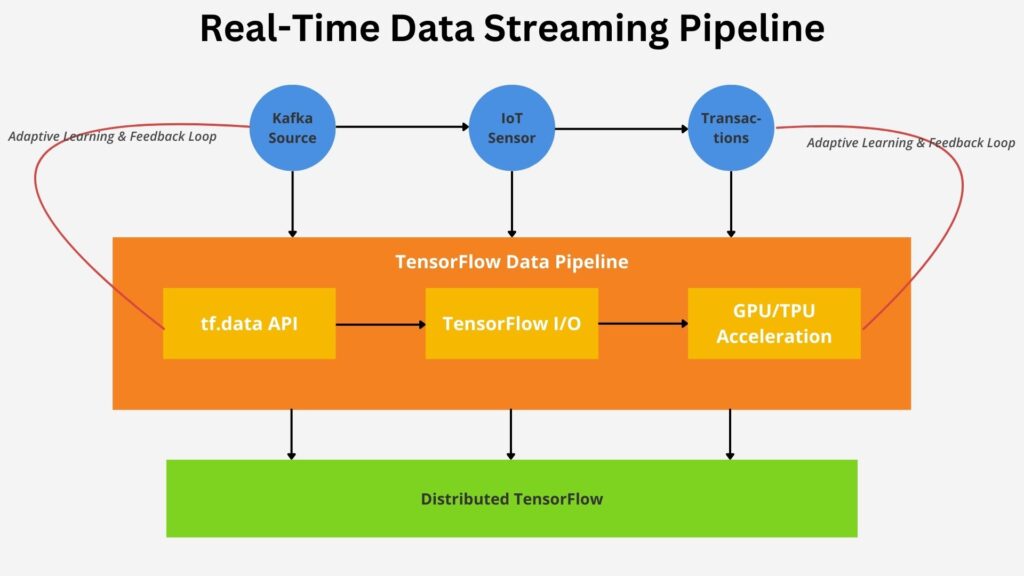
TensorFlow provides several tools supporting real-time data streaming. Real-time data streaming depends upon efficient data and preprocessing at scale and the tf.data API supports this. Often, data is sourced from streaming tools like Apache Kafka that need to connect to the TensorFlow model. TensorFlow I/O facilitates connections to these streaming tools. Utilizing distributed processing to handle large datasets in real-time is necessary. Distributed TensorFlow architecture supports this need by allowing pipeline scaling for large datasets. TensorFlow also allows GPU and TPU accelerations that optimize real-time computations. It is helpful whenever pipelines evolve with incoming data, and TensorFlow will enable developers to build adaptive learning loops to facilitate this. Please check out Optimize TensorFlow Data Pipelines for Faster, Smarter Models as well.
2.4 Challenges and Solutions in Real-Time Streaming with TensorFlow
The significant challenges associated with real-time streaming include data quality, latency, and model drift. Poor data quality can adversely affect model accuracy, making its management critical. TensorFlow addresses this by handling out-of-sequence data through specialized functions. Latency affects overall model performance and must be kept within certain bounds by pipeline optimization and resource scaling. TensorFlow provides monitoring tools that assist with identifying bottlenecks in real-time streams. Model drifts impact overall model accuracy where minimization is essential. TensorFlow delivers the ability to incorporate feedback loops that help to minimize model drift.
Section 3: Automating Hyperparameter Tuning Using TensorFlow Techniques for Big Data
3.1 Understanding Hyperparameter Tuning in Big Data Models
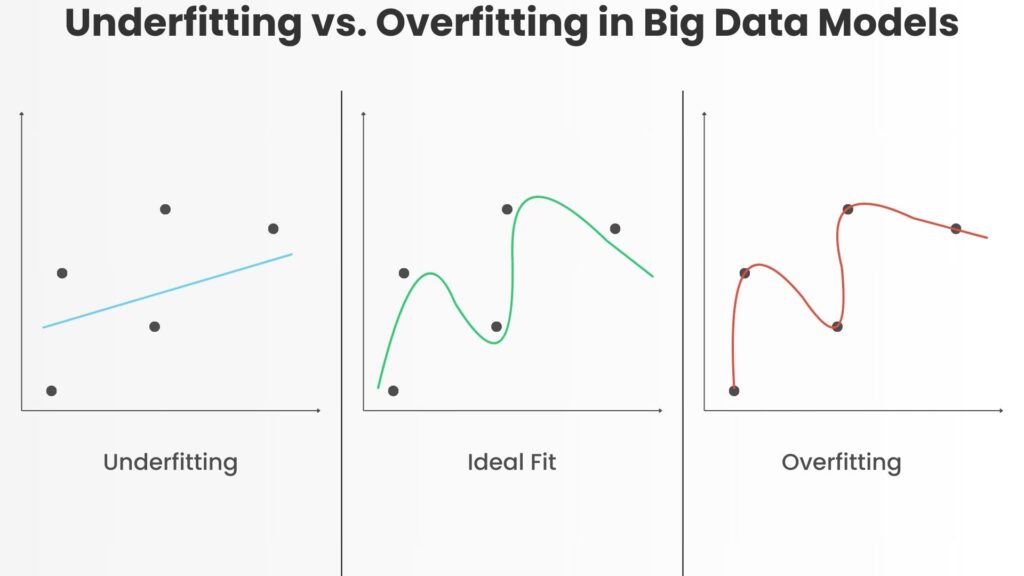
ML models must balance complexity to avoid underperforming or overfitting on vast datasets. Models underperform when they fail to capture essential patterns, resulting in poor accuracy. In other words, they fail to generalize well from unseen training data. The other extreme is overfitting, where they fit the training data too well and perform poorly on any new data.
Therefore, developers must tune their models to avoid underperforming or overfitting. This technique, called hyperparameter tuning, maximizes model performance at scale. TensorFlow Techniques for Big Data provides a set of hyperparameter tuning techniques that help models remain efficient and scalable. Automated tuning is another crucial facility that reduces computational waste while enhancing model accuracy. TensorFlow also provides scalable tuning workflows that streamline development for data scientists.
3.2 TensorFlow Techniques for Big Data: Optimizing Model Accuracy
TensorFlow is helpful because it provides automated methods for refining complex big data models. It also offers advanced optimization techniques for adapting to evolving datasets and structures. TensorFlow also enables developers to perform efficient hyperparameter tuning that maximizes computational resources. It provides adaptive algorithms that improve model robustness. Another toolset is scalable tuning frameworks that ensure consistent performance.
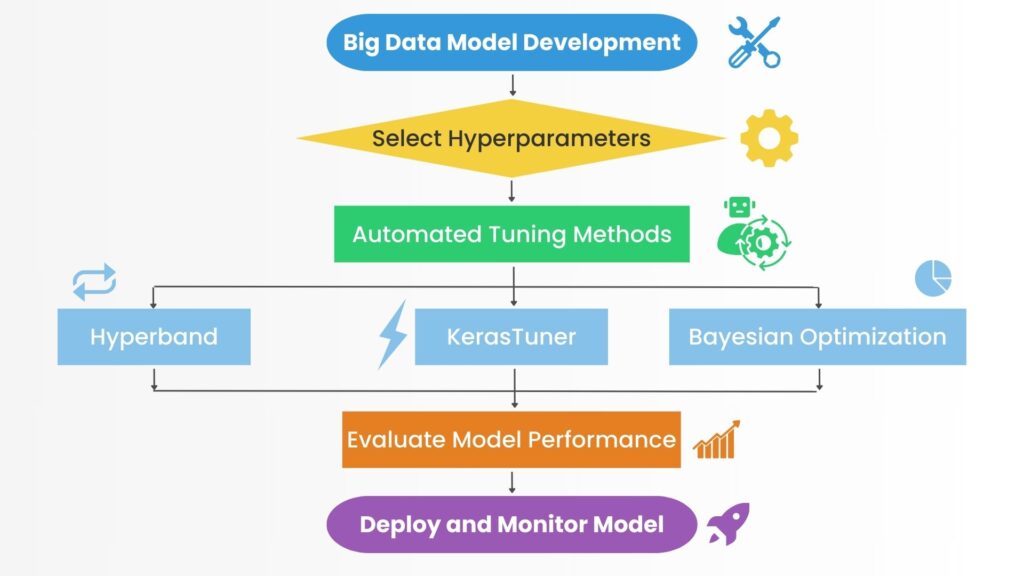
3.3 Key TensorFlow Tools for Hyperparameter Optimization
We have discussed various techniques that TensorFlow allows to tune and optimize model performance. We will now consider specific tools enabling developers to perform these techniques. KerasTurner allows developers to simplify and accelerate hyperparameter tuning for large datasets. Another tool is Hyperband, which dynamically adjusts resource allocation to optimize results. Whenever probabilistic methods are needed, these are provided by Bayesian optimization, allowing model improvement. Distributed tuning across TensorFlow clusters is available whenever the model needs parallel processing. TensorFlow allows tuning through GPUs and TPUs, which reduces overall tuning time. These ideas are also discussed in Building and Training TensorFlow Models.
3.4 Real-World Applications of TensorFlow Techniques for Big Data
As related, TensorFlow Techniques for Big Data through predictive analytics models drive innovation in healthcare, finance, and retail. Automated hyperparameter tuning is one such technique that significantly benefits predictive analytics models. This also substantially reduces manual oversight when improvising accuracy for real-time big-data systems. This makes their implementation and deployment far more efficient. Hyperparameter tuning is also needed in production environments and not only in development environments. TensorFlow provides scalability and automation, supporting hyperparameter tuning in production environments and continual performance improvements.
Section 4: TensorFlow Techniques for Big Data Model Deployment and Scaling
4.1 The Importance of Scalable Model Deployment
While building an effective model is paramount, due consideration must be given to deploying these models in production environments. These deployments must also scale efficiently to meet big data demands and handle large datasets. When building models, it is necessary to make them scalable to ensure consistent performance under varying workloads. Many models need to process data in real-time. Therefore, development must build these models with dynamic and adaptive deployment strategies. TensorFlow Serving is a TensorFlow framework component that enables seamless and distributed model deployment. Also, TensorFlow pipelines facilitate continuous integration and delivery of models. Developers can maintain and update models in response to changing requirements and scenarios.
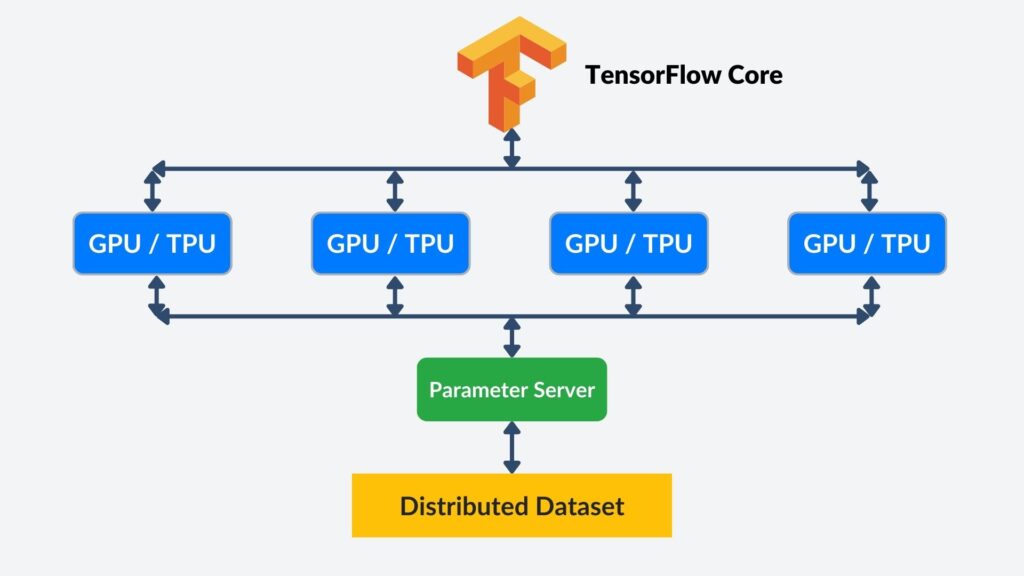
4.2 TensorFlow Techniques for Big Data: Distributed Model Training
Often, it is necessary to train models with immense data volumes. Therefore, it is essential to set up distributed training to ensure effective data handling. TensorFlow provides the tf.distribute API that optimizes training across multiple GPUs or TPUs. This parallelism strategy distributes tasks, resulting in enhanced computation efficiency. Another aspect of parallelism is distributed datasets that prevent memory bottlenecks during training. Additional techniques include parameter servers that help to improve coordination in distributed environments. Please also look at Building and Training TensorFlow Models for extra points.
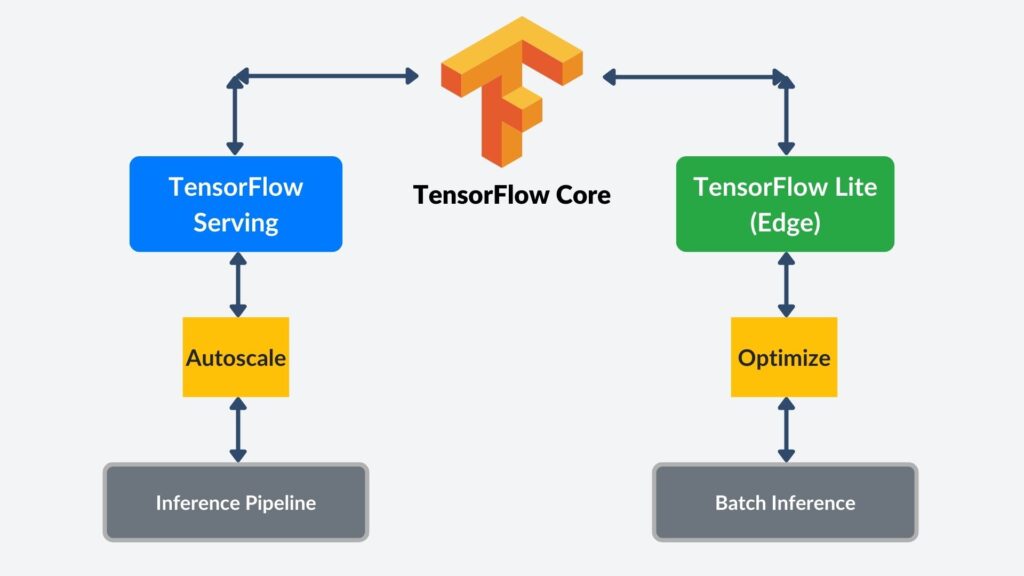
4.3 TensorFlow Techniques for Big Data: Scaling Inference Pipelines
Models often process immense data volumes in real time and operate as high-throughput systems. This is particularly true for edge devices that often do not have the computational resources as cloud servers. Therefore, developers must deploy them as scalable inference pipelines to guarantee performance. TensorFlow Lite is a framework component that optimizes models for edge devices without compromising performance. Another framework component is Autoscaling TensorFlow Serving, which adapts to fluctuating data request volumes. The TensorFlow framework also includes batch inference that processes large datasets efficiently, minimizing resource consumption. Additionally, it is essential to deploy advanced load-balancing strategies to maintain pipeline reliability and speed.
4.4 Advanced TensorFlow Strategies for Deployment Optimization
When deploying TensorFlow models, you need to consider the computational resources available. You often must deploy hybrid solutions that include both on-premises and cloud systems. However, you can integrate TensorFlow with these configurations. You can also customize TensorFlow operators to enhance compatibility with unique data workflows. TensorFlow allows model compression to address deployment latency and limited storage needs.
Even the best-designed models will drift over time, and detecting and rectifying this is necessary. TensorFlow makes this achievable through continuous monitoring to ensure model robustness over time.
Another important strategy is federated learning, in which data is never transferred from its source. This is necessary because of privacy and security regulatory requirements. TensorFlow supports distributed data to ensure privacy and security obligations are adhered to.
Conclusion: Mastering TensorFlow Techniques for Big Data Success
We have briefly studied several of TensorFlow’s advanced capabilities, especially those required by real-world use cases. Scaling and optimization are needed to handle big data. Models increasingly must process real-time data, and TensorFlow allows real-time data streaming. It also provides hyperparameter tuning to enhance performance. Real-world data often does not nicely fit ML models, and TensorFlow addresses this through feature engineering tools. Big data can overload ML model servers, and TensorFlow allows distributed deployment to handle big data loads. Employing these techniques empowers businesses to remain competitive in data-driven industries. Companies must master these techniques for big data to ensure future scalability and success.
Recommended Further Reading
Mastering Predictive Analytics with scikit-learn and TensorFlow
Author: Alan Rushton
This book offers insights into predictive analytics by utilizing TensorFlow and scikit-learn, helping readers build efficient and scalable machine learning models.
Predictive Analytics with TensorFlow
Author: Md. Rezaul Karim
A practical guide to implementing predictive analytics using TensorFlow with real-world examples to help extract valuable insights from data.
TensorFlow Machine Learning Cookbook
Author: Alexia Audevart
A collection of recipes designed to help you quickly solve common machine learning challenges using TensorFlow, from data ingestion to deployment.
Mastering TensorFlow 2.x
Author: Rajdeep Dua
This book delves into building and scaling neural networks using TensorFlow 2.x, covering diverse data types and time series forecasting.
Learn TensorFlow Enterprise
Author: Karthik Muthuraman
A complete guide to deploying and managing TensorFlow models in enterprise environments, focusing on cloud integration and scalability.